多数のAWSアカウントに散在するEC2インスタンス群をAnsibleで一括管理する話
これは ドワンゴ Advent Calendar 2025 の9日目の記事です。
はじめに
こんにちは。クラウド構築運用部PaaSセクションの尾﨑です。
この記事では、多数のAWSアカウント上に分散して存在するEC2インスタンス群(仮想マシン群)をAnsibleで一括管理する方法に関して書いていきます。私の所属するチームでは、ある一群のWebサイトのインフラ構築・管理を担当しているのですが、その際に上記のような一括管理が必要になったため、調査とPoCを経てこの記事で説明するような仕組みを導入しました。調査の際に同様の事例の情報をあまり見つけられなかったこともあり、ここに知見を共有したいと思います。
文脈――解くべき問題
昨年6月、弊社はサイバー攻撃の被害を受けました。被害は広範囲に及びましたが、その中にプライベートクラウド上の仮想マシンでホストしていた多数のWebサイトもありました。今回私たちのチームが携わっていたのはこれらのWebサイトの一部をAWS上へ移設復旧するプロジェクトです。
ひとえにWebサイトといっても、当然ながらそれぞれ異なった目的で、異なった対象者に向けて、異なった技術によって作られています。今回は、復旧対象のうち同様の技術でつくられていたある一群のWebサイトを私たちのチームで担当することになりました。
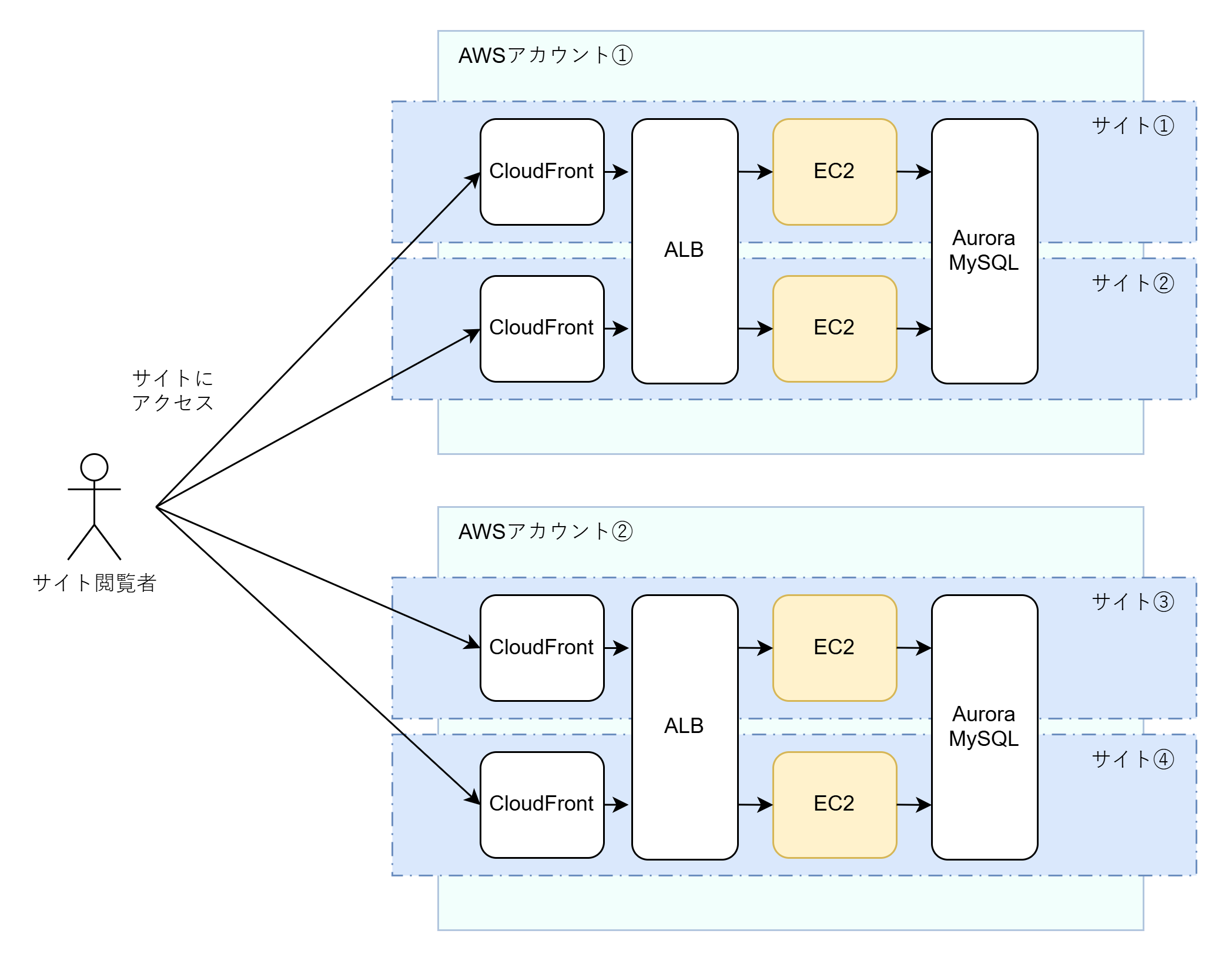
復旧先の大まかなインフラ構成は、次のようになりました。まずCloudFront (CDN)でリクエストを受け、ALB(L7ロードバランサ)を通してEC2インスタンス(Linux仮想マシン)にリクエストを導く。EC2インスタンスではWebサーバーとアプリケーションサーバーが立っていて、必要に応じてAurora MySQL (RDBMS)に問い合わせる……というもの。至って普通の構成です。
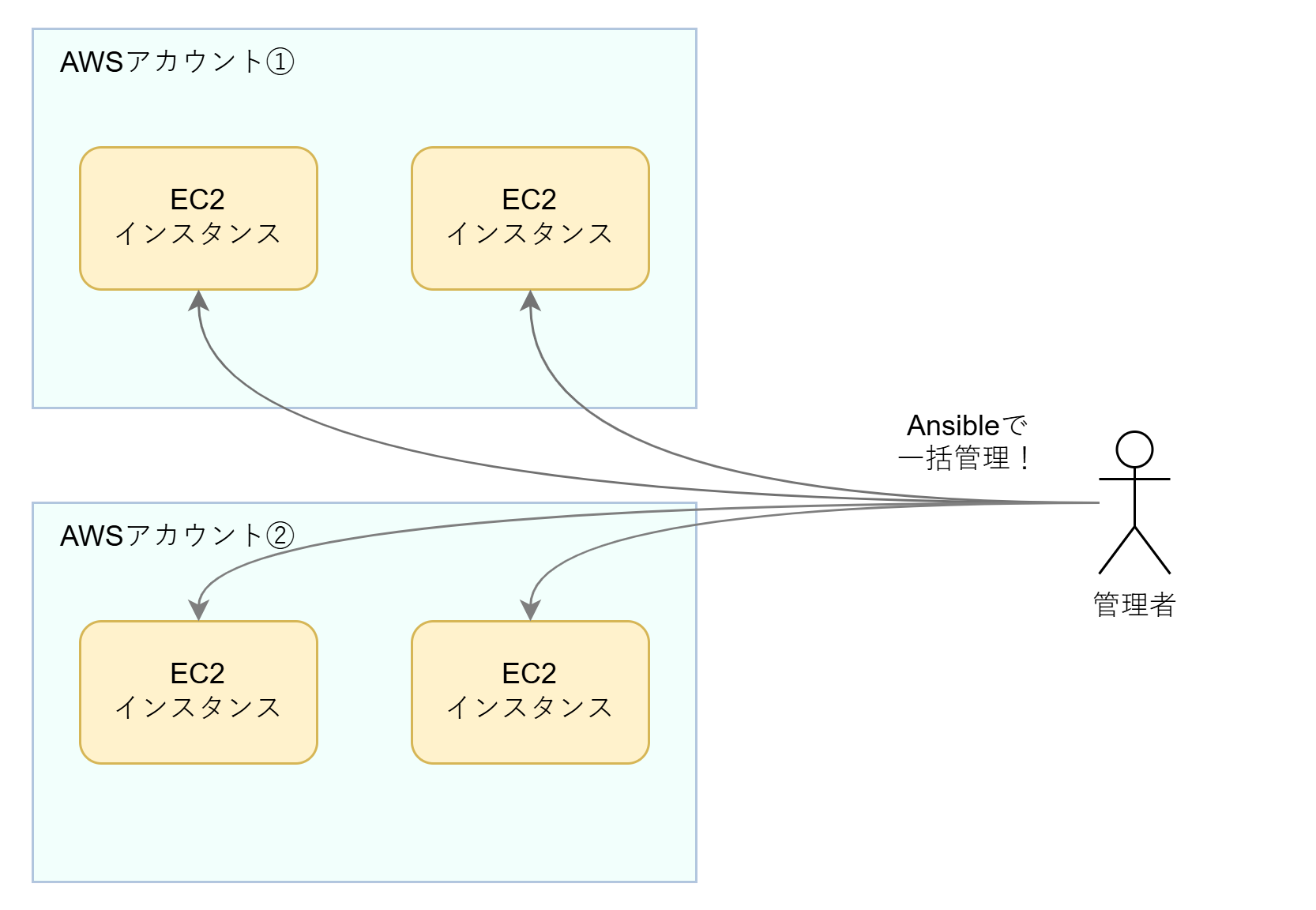
ただ、やや特殊な点として、全てのWebサイトを1つのAWSアカウント1で復旧させるのではなく、複数のAWSアカウントで復旧させるという要件がありました。これは、Webサイトの運営元(部署)が多岐にわたるため、費用の計算をしやすくするために一定の部署の単位でAWSアカウントをつくることになったという事情によるものです。
複数のAWSアカウントに分けて構築するとはいえ、各サイトでほぼ同様のインフラ構成となるため(そもそもこれらのサイトをまとめて担当することになったのはそれが理由です)、できる限り一括で管理したいです。そのため、私たちのチームでは様々なIaC (Infrastructure as Code)技術で管理の省力化を図りました。
AWSリソースの基本的な管理は、ほぼTerraformで行いました。ここについては今後別の記事で書いていただくことになっているので詳細は省略しますが、Terraformのモジュール機能やマルチプロバイダなどによって、システムの大部分をうまく管理できるようになりました〔追記:こちらの内容は 実践Terraform:マルチAWSアカウント環境の構成管理とモジュール分割 をご覧ください〕。
ただ、Terraformでは管理できない部分があります。それは「EC2インスタンスの中」です。TerraformのAWSプロバイダで管理できるのは、AWSのAPIで管理できるリソース、つまるところ「ガワ」であって、そのリソースの中身であるデータについては管理の対象外になっています。しかし、EC2インスタンスの中も、例えばdnfによるソフトウェアのインストール、Apacheなどのミドルウェアの設定、systemdやcronの設定、監視のためのエージェント設定など、一括で管理したいものがあります。ここにもIaCの需要があるわけですが、残念ながらここはTerraformの守備範囲外なのです。
プロジェクトの中でも初期段階、つまり各サーバーの構築段階では初期構築用のシェルスクリプトを実行することで事足りていました。しかしながら、継続運用を考えると、「何らかの変更を全サイトのEC2インスタンスで行う際には、全インスタンスにログインしてそれぞれでシェルスクリプトを実行する必要がある」というのでは大変です。そのため、EC2インスタンス内を一括管理できる手段を模索することになりました。
技術選定
さて、このようなEC2インスタンスの中の管理、一般的な言葉で言うと仮想マシン内の管理を行うツールはひとつのジャンルを成しており、一般に「構成管理ツール」と呼ばれます。その代表的なものが、AnsibleやItamae、Chefなどです。
今回は、構成管理ツールとして Ansible を選びました。
理由のひとつは、社内での実績が豊富だったことです。プライベートクラウド(オンプレミス)上の仮想マシンの管理では、Ansibleが広く使われていました。そのため、今回の復旧プロジェクトのメンバーや運用の引き継ぎ先のメンバーの学習コストが低いことが想定できました。
もうひとつの理由は、後述するようなSession Managerを利用したEC2インスタンスへのログインを簡易に実現できる方法がAnsible以外のツールでは見つからなかったことです。
Ansibleで望ましい結果が得られないようであれば別の方法を探索していましたが、PoCの結果欲しい性質が問題なく得られたため、そのまま後述のようなAnsibleを利用した構成を採用することになりました。
アーキテクチャ
さて、繰り返しになりますが、今回欲しいのは、
- 複数のAWSアカウントにある、
- 複数のEC2インスタンスに対して、
- できれば1回の実行でまとめて、
- 同じ設定を流し込める
管理のしくみです。
これをどう実現するのかという話になりますが、そのためにまずAnsible自体のアーキテクチャについて軽く説明しておきます。
Ansibleというのは、簡単にいうと複数のサーバーにSSHで接続してコマンドを実行してくれるようなツールです2 3。実際は単純なコマンド実行と違って、「Nginxがインストールされている状態にする」といった「望む状態」を書くことで冪等性を満たすようにするというのが一つ大事な点ではあるのですが、本記事の主題とはあまり関係ありませんので省略します。
「複数のサーバーにSSHで接続してコマンドを実行」と書いたように、一般的には管理対象のホスト(サーバー)とは別に、Ansible実行用のホストを用意します。ここで、Ansibleを実行するホストを「コントロールノード」、Ansibleによって管理されるホストを「マネージドノード」4と言います。コントロールノードで ansible-playbook コマンドを実行すると、用意していた設定ファイルに書かれている状態になるようにマネージドノードに対してコマンドが送られる、という形です。なお、コントロールノードにはAnsibleの処理系のインストールが必要ですが、マネージドノードのほうにはAnsibleの処理系は不要で、Pythonの処理系が入っていればよいです。
……というのがよくある使い方なのですが、実は、コントロールノードとマネージドノードを同じにするような使い方もあります。あるホストで ansible-playbook コマンドを実行して、そのホスト自身に対してコマンドを送るような使い方です。
この点、すなわち
- 「マネージドノード≠コントロールノード」とする
- 「マネージドノード=コントロールノード」とする
のどちらを選ぶかというのが、一つのアーキテクチャ的な考慮点になります。
SSH接続できる多数のサーバーを管理するような用途では、普通はマネージドノードと別にコントロールノードを用意すると思います。しかし、例えば管理したい対象がAWSリソースやネットワーク機器等APIで操作するものの場合は、Ansibleはコントロールノード上でAPIを叩くという操作を実行するため、マネージドノードはコントロールノードと一致します。
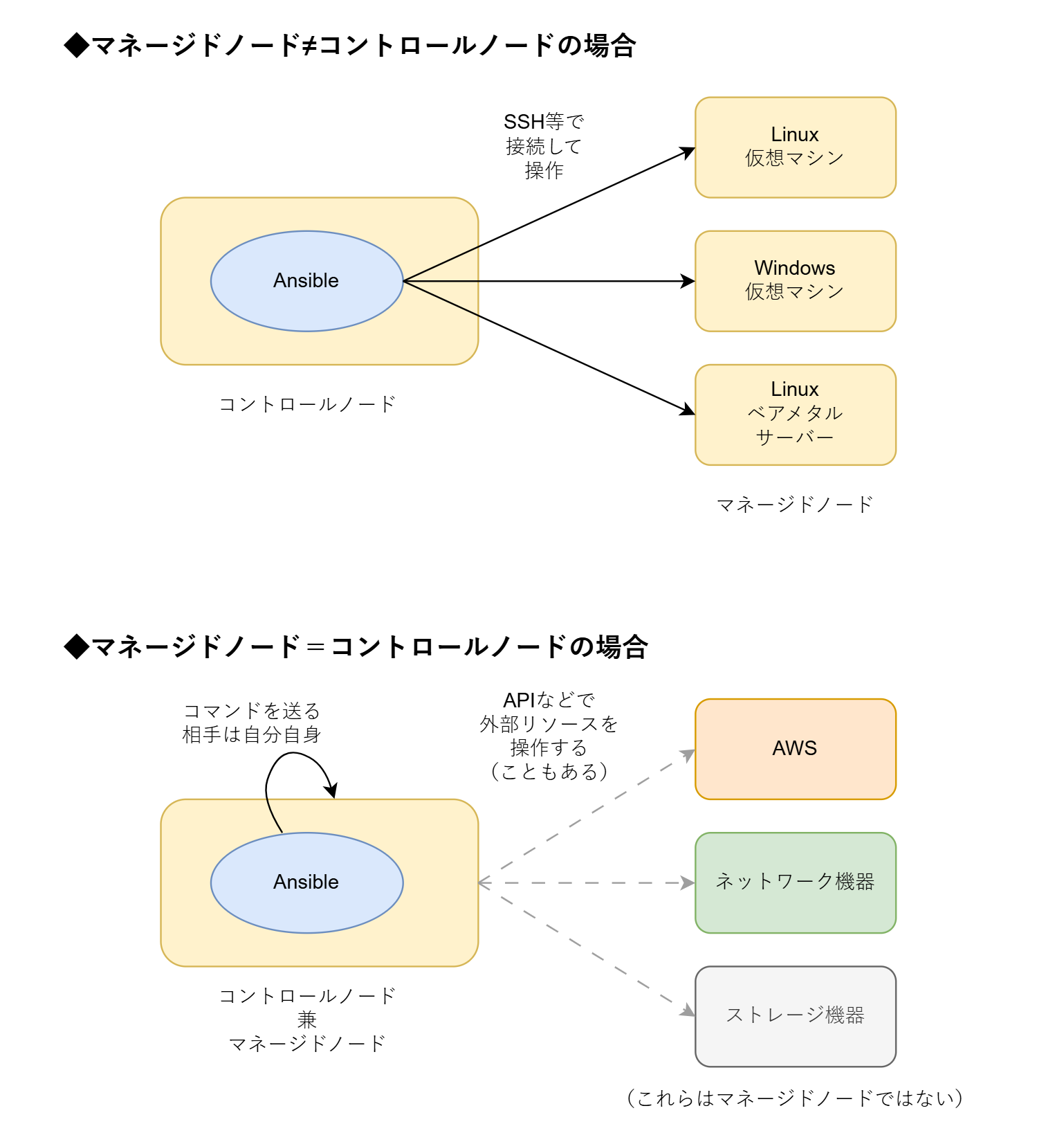
実は、最もAWSマネージドな(?)Ansible実行方式は、「マネージドノード=コントロールノード」のほうです。これは、EC2インスタンス上で単発のコマンドを実行できる AWS Systems Manager Run Command という機能のプリセットにある「ドキュメント」(≒スクリプト)の1つ、AWS-ApplyAnsiblePlaybooksを利用するという方法になります。このドキュメントを実行することで、対象のEC2インスタンスにAnsibleをインストールし、そのインスタンス自身をマネージドノードとして ansible-playbook を実行するという一連の操作を行うことができるのです。
しかしながら、この方法は、以下のような難点があります。
- AWSサービスがAnsibleの定義ファイルをダウンロードしてきて利用するため、Ansible定義ファイルを一度S3バケットかGitリポジトリに配置する必要がある。ローカルマシンから手軽に実行することができない。
- 実行時のログがS3バケット(オブジェクトストレージ)に格納される5ため、確認が面倒。
- EC2インスタンスにAnsibleをインストールすることになるため、管理するものが増える(状態を持つ部分が増える)。特に、Ansibleのアップデートがある場合などの対処が煩雑になるおそれがある。
- Ansibleから見たときの実行対象が
localhostになってしまう。Ansibleにはhost_varsやgroup_varsといった、対象ホストごとに別の変数を渡せる仕組みがあるのだが、これが使えない。
そのため、こちらはあまり良い方法とは思えませんでした。特に、「EC2インスタンスにAnsibleをインストールしたくない」という点を考えると、やはり普通のVM(仮想マシン)管理と同様に「マネージドノード≠コントロールノード」とする方向でいくのがよさそうです。
さて、この「マネージドノード≠コントロールノード」とするアーキテクチャをとるにしても、いくつか方式が考えられます。というのは、AnsibleからEC2インスタンス内に接続する方法(つまり、コントロールノードからマネージドノードに接続する方法)がいくつかあるからです:
- Session Manager で接続する方法
- EC2 Instance Connect で接続する方法
- コントロールノード用のEC2インスタンスを用意して、そこから普通のSSHで接続する方法
今回は、Session Managerで接続する方法を選びました。この方法だと、別のEC2インスタンスを用意する必要がないためコストがかからず、EC2 Instance Connect で接続する場合のようにSSH鍵の管理で困ることもありません。詳細は後述しますが、AWS CLIで利用できるIAMの認証情報だけ用意すれば、通常のSSHと同じような使い勝手で接続することができます。EC2インスタンスをAnsibleで管理したい多くの場合で、この方法が第一候補になるのではないかと思います。
実装編(前編)――1つのEC2インスタンスを管理する
では、ここからはどのようにして実現するかを、設定ファイルのコードを示しつつ解説します。とはいえ一気に説明するとややこしいので、まず前半では1つのEC2インスタンスをAnsibleで管理する方法を示し、後半でそれを複数インスタンスへ展開する方法を説明しようと思います。
「1つのEC2インスタンスを管理する方法」というと極めて基本的なことに聞こえるかもしれませんが、実際はそれほど簡単ではありません。AnsibleはVMにIPアドレスで直接SSH接続できるような世界観で使いやすいツールで、パブリッククラウド対応は後付けという趣が強いのがその一因でしょう6。
インベントリ
まずは、EC2インスタンスを探す方法についてです。Ansibleには「インベントリ」という仕組みがあります。端的に言うと、インベントリは「接続先のホスト(サーバー)のリスト」です。例えば、
# ===== ホスト一覧 =====
[all]
server1 ansible_host=192.168.10.11
server2 ansible_host=192.168.10.12
server3 ansible_host=192.168.10.21
server4 ansible_host=192.168.10.22
# ===== グループ定義 =====
[web]
server1
server2
[db]
server3
といった風に、サーバーのリストを書きます(上記はINI形式の例ですが、YAML形式でも書けます)。
ホストのリストとは言いましたが、単純な列記だけでなくサーバーの種別などによってグループ化(タグ付け)することもでき、上記の例では、 server1 と server2 を web グループに、server3 と server4 を db グループに所属させています。このようなインベントリを用意しておくと、Ansibleの定義ファイル(「プレイブック」といいます)にhosts: webと書いてWebサーバーの仮想マシンにだけNginxをインストールする、といったことができます。
上で示したINI形式のインベントリはAnsibleの実行前に予め用意していくファイルですが、事前に用意するのではなく、Ansibleの実行時に何らかの情報源から自動的にインベントリを生成することもできます。これを「動的インベントリ」といいます。
この動的インベントリの一つに、Amazon.Aws コレクションに含まれる amazon.aws.aws_ec2 inventory があります。これを使うと、Ansible実行時にAWS APIを利用してEC2インスタンスの一覧を取得してくれます。
例えば、以下のように aws_ec2.yaml という名前の設定ファイルをつくるとします。
inventories/aws_ec2.yaml:
plugin: aws_ec2
aws_profile: default
regions:
- ap-northeast-1
filters:
instance-state-name: running
hostnames:
- tag:Name
keyed_groups:
- key: tags.Organization
prefix: org
- key: tags.Service
prefix: svc
- key: tags.Env
prefix: env
このファイルをインベントリとして指定すると、EC2インスタンスがAnsibleに認識されます。
$ ansible-inventory --graph -i inventories
@all:
|--@ungrouped:
|--@aws_ec2:
| |--org1-service1-prod-ec2
| |--org1-service2-dev-ec2
| |--org1-service2-prod-ec2
| |--org1-service1-dev-ec2
|--@env_prod:
| |--org1-service1-prod-ec2
| |--org1-service2-prod-ec2
|--@env_dev:
| |--org1-service2-dev-ec2
| |--org1-service1-dev-ec2
|--@org_org1:
| |--org1-service1-prod-ec2
| |--org1-service2-dev-ec2
| |--org1-service2-prod-ec2
| |--org1-service1-dev-ec2
|--@svc_service1:
| |--org1-service1-prod-ec2
| |--org1-service1-dev-ec2
|--@svc_service2:
| |--org1-service2-dev-ec2
| |--org1-service2-prod-ec2
単純に認識させるだけではなく、 keyed_groups の記述を元にグループ分けも行ってくれます。例えば、 keyed_groups に key が tags.Env で prefix が env の項目を入れると、「EC2インスタンスにEnv: prodというタグがある場合は、Ansible側で env_prod というグループに所属させる」という処理をしてくれます。AWS側でつけたメタデータをAnsible側でも使えるようになるわけです。なお、ここでOrganizationとServiceは部署とサービス名(サイト名)を示す識別子で、EC2ホスト名(Nameタグ)は ${Organization}-${Service}-${Env}-ec2 でつけるようにしています(あくまで今回のプロジェクト特有の規約です)。
また、デフォルトではAnsibleで使うホスト名はEC2のID(i-で始まる自動生成のID)になりますが、 hostnames に tag:Name を指定することで、 Name タグの値をAnsible側のホスト名として扱えるようになります。
これでEC2インスタンスを探して選ぶ部分ができました。
SSM接続プラグイン
次は、その見つけたEC2インスタンスにコマンドを流し込む部分です。ここでは、Amazon.Aws コレクションに含まれる amazon.aws.aws_ssm connection プラグインを使います。これは、Session ManagerでEC2インスタンスに接続できるようにしてくれるプラグインです。
このプラグインを使って接続するようにするためには、先ほどのインベントリの設定ファイルを編集します7。
inventories/aws_ec2.yaml:
plugin: aws_ec2
aws_profile: default
regions:
- ap-northeast-1
filters:
instance-state-name: running
hostnames:
- tag:Name
keyed_groups:
- key: tags.Organization
prefix: org
- key: tags.Service
prefix: svc
- key: tags.Env
prefix: env
# ここを追加する
compose:
ansible_connection: "'aws_ssm'"
ansible_aws_ssm_profile: "'default'"
ansible_aws_ssm_region: "'ap-northeast-1'"
ansible_aws_ssm_bucket_name: "'sample-ansible-bucket'"
ansible_host: instance_id
compose に指定することで、プレイブック側に変数を渡してやることができます。 ansible_connection に aws_ssm を指定し、 ansible_aws_ssm_profile などの変数で使うプロファイルやリージョンを指定します。ここで注意が必要なのは ansible_aws_ssm_bucket_name で、ここに指定するのはファイル受け渡しに利用するS3バケットの名前です。 aws_ssm connection プラグインはファイルの転送の際に一度S3バケットにファイルを配置するので、別途S3バケットを用意する必要があります。また、composeの中で文字列を指定する場合は、例に示したように、二重引用符と一重引用符とを組み合わせた特殊な書き方にする必要があります(Jinja2テンプレートとして評価されるため)。
このプラグインが、今回のようなアーキテクチャを実現するための肝となる部品です。他の方法だと接続用のSSH鍵の管理の必要が発生するなどの面倒な要素がありますが、この aws_ssm connection プラグインを利用すると、AWSの認証・認可の基盤にうまく乗っかって低い管理コストでセキュリティを担保できます。なお、このSSMプラグインはもともとコミュニティ開発の Community.Aws コレクション に含まれていましたが、今年Ansibleチームが管理する Amazon.Aws コレクション に取り込まれました。
以上で説明したように、aws_ec2 inventory と aws_ssm connection の2つの仕組みを使うことで、1つのEC2インスタンスをAnsibleで管理することができるようになります。
sample-playbook.yaml:
- name: Ping all hosts
hosts: all
gather_facts: false
tasks:
- name: Ping all hosts
ansible.builtin.ping:
実行:
# 対象のインスタンスにプレイブックを流す
# --check はドライランオプション
$ ansible-playbook -i inventories -l ${インスタンスID} --check sample-playbook.yaml
実装編(後編)――複数のEC2インスタンスを管理する
後編では複数のEC2インスタンスに対してAnsibleを流す方法を解説します。
同じAWSアカウントの複数のEC2インスタンスを管理する
まず、対象とするEC2インスタンスが同じAWSアカウントの中にある場合ですが、これはインスタンスが一つのときと同じです。何か特別な追加の準備は要りません。EC2用動的インベントリがそのAWSアカウントにあるEC2インスタンスの情報を全て取得してくれるからです。
むしろ、Ansibleプレイブックに何も考えずに hosts: all などと書いているとホスト全てに対して実行されるので、複数EC2インスタンスが存在する場合に「1つだけに流す」場合には hosts か -l コマンドラインオプションで対象ホストを明示的に指定しないといけません。
複数のAWSアカウントへの接続
問題はここからで、複数のAWSアカウントに分散してEC2インスタンスがある場合には、話が複雑になってきます。EC2インスタンスを操作する際、それぞれのインスタンスが所属するAWSアカウントに応じて権限を使い分ける必要があるからです。とはいえ、若干複雑ではあるものの、AWSにはこのような権限の使い分けを行う方法があり、またAnsible側もそれに対応しているため、複数AWSアカウントへの接続は実現可能です。
AWS CLIには「プロファイル」というものがあり、これを切り替えることで、別のAWSアカウントのIAMユーザーの、あるいは同じAWSアカウントの別のIAMユーザーの権限でAPIを叩くことができるようになります。
例えば、 ~/.aws/config に
[profile profile1]
region = ap-northeast-1
[profile profile2]
region = ap-northeast-1
のように2つのプロファイルが定義されているとき8、
# profile1 で実行(事前にprofile1でログインできる認証情報を用意する必要あり)
$ aws s3 ls --profile profile1
# profile2 で実行(事前にprofile2でログインできる認証情報を用意する必要あり)
$ aws s3 ls --profile profile2
のようにオプションを渡せばそれぞれ別の権限で実行することができます。
しかし、これを漫然と使うだけだと、プロファイルごとに別の認証情報を得る必要があります。例えば20個のAWSアカウントにまたがるEC2インスタンス群を操作するならば、20個のアクセスキーを発行して設定する必要があるといった具合です。MFAの手間も考えるとこれは現実的ではありません。こうではなく、1つの認証情報を用いて複数のAWSアカウントの操作の認可を得る方法がほしいわけです。
これを実現するのが、IAMロールの引き受けという仕組みです。あるAWSアカウントのリソースを操作する権限(IAMロール)を別のAWSアカウントの権限主体(IAMユーザーなど)に与えることができるのです。これを利用して、ユーザーは一旦ひとつのアカウントにログインし、個別のアカウントにはそこからロールを引き受けることでアクセスする、という仕組みを作れます。世の中では、「踏み台アカウント」とか「Jumpアカウント」とか呼ばれている方法です9。
今回は、EC2やAuroraといった実際のWebサイト向けのリソースを置くAWSアカウント群とは別に、管理用のリソースを置くためのAWSアカウント(以下では「管理用AWSアカウント」と書くことにします)を用意しました。その管理用AWSアカウントにログインし、そこから更に各AWSアカウントのIAMロールを引き受けるようにすることで、一つの認証情報で各AWSアカウントのEC2インスタンスを操作を行えるようにしました。
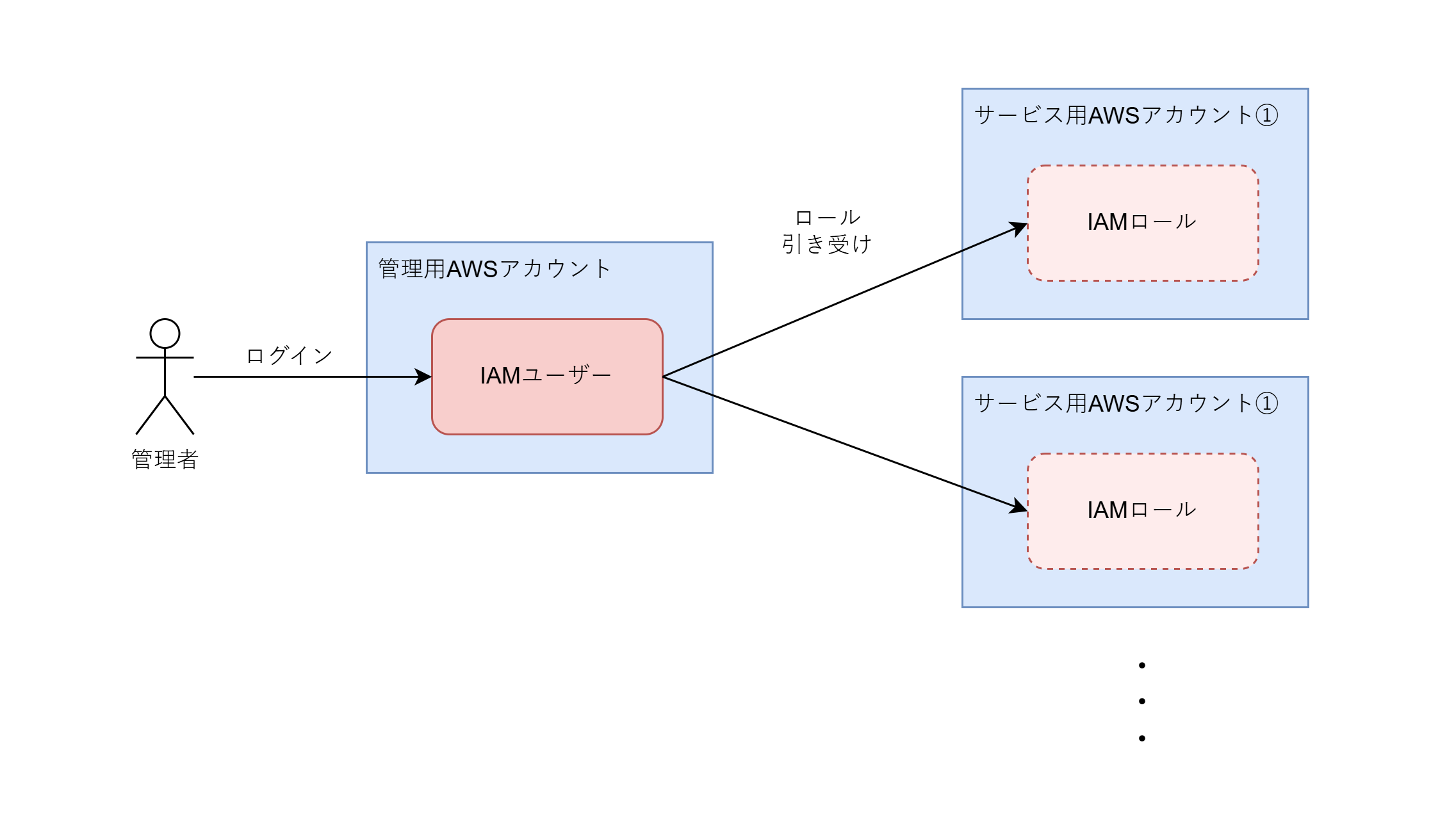
つまり、以下のように management プロファイルと、それを source_profile に設定した profile1 、 profile2 を定義することで、
[profile management]
region = ap-northeast-1
[profile profile1]
role_arn = arn:aws:iam::${アカウント1のアカウントID}:role/ansible-role
source_profile = management
region = ap-northeast-1
[profile profile2]
role_arn = arn:aws:iam::${アカウント2のアカウントID}:role/ansible-role
source_profile = management
region = ap-northeast-1
以下のように management でログインできる認証情報で profile1 、 profile2 でも実行できるようになります。
# managementで実行(事前にmanagementでログインできる認証情報を用意する必要あり)
$ aws s3 ls --profile management
# profile1 で実行(事前にmanagementでログインできる認証情報を用意する必要あり)
$ aws s3 ls --profile profile1
# profile2 で実行(事前にmanagementでログインできる認証情報を用意する必要あり)
$ aws s3 ls --profile profile2
これで、AWS CLIを用いて複数のAWSアカウントのリソースを操作する仕組みはできました10。次は、これを利用してAnsibleを動かす設定をしていきます。
動的インベントリの設定
EC2用動的インベントリの設定は、aws_ec2.yamlで終わる名前のファイルに書くという決まりになっています。複数AWSアカウントに対応させるには、そのようなファイルをAWSアカウントごとに1つずつ作っていきます(実際はスクリプトで自動生成しました)。
例えば、 inventories/account1_aws_ec2.yamlに以下のように書きます。
plugin: aws_ec2
aws_profile: profile1 # プロファイルを指定
regions:
- ap-northeast-1
filters:
instance-state-name: running
hostnames:
- tag:Name
keyed_groups:
- key: tags.Organization
prefix: org
- key: tags.Service
prefix: svc
- key: tags.Env
prefix: env
compose:
ansible_connection: "'aws_ssm'"
ansible_aws_ssm_profile: "'profile1'" # プロファイルを指定
ansible_aws_ssm_region: "'ap-northeast-1'"
ansible_aws_ssm_bucket_name: "'sample-ansible-bucket-account1'"
ansible_host: instance_id
これらをアカウントの数だけつくって inventories ディレクトリに格納します。同じディレクトリに入れることで、ansible-playbook -iのオプションにそのディレクトリを指定するだけで全てのAWSアカウントにあるEC2インスタンスを見つけられるようになります。
$ ansible-inventory --graph -i inventories
SSM接続プラグインの設定
Session Manager で接続するときのプロファイルは、前節の例のように、動的インベントリのcomposeブロックの ansible_aws_ssm_profile で指定します。 aws_profile のほうに指定するのがEC2インベントリで利用するプロファイル、 ansible_aws_ssm_profile のほうに指定するのがSSM接続プラグインで利用するプロファイルであることに注意してください。
実現
以上のようにセットアップすることで、たくさんのAWSアカウントにまたがって存在するたくさんのEC2インスタンスに設定を流し込むことができます。特定の環境にのみ流すことも、コマンドラインオプション指定だけでできます。
# 全部に流す
$ ansible-playbook -i inventories sample-playbook.yaml
# dev環境のみに流す
$ ansible-playbook -i inventories -l env_dev sample-playbook.yaml
# service1サービスのみに流す
$ ansible-playbook -i inventories -l svc_service1 sample-playbook.yaml
これで、systemdの設定を一括で変更したくなったり、全サイトのApacheログをまとめてダウンロードしたくなったりしても、簡単に対応できるようになりました!
CI/CD
CI/CDは、GitHub Actionsで実装しました。
CIとしては、Ansible関係の変更があるPull Requestの場合に開発環境へのドライランの実行を行うようにしました。CDとしては、workflow dispatchによってGitHub ActionsのUI上から実行できるようにしました。
AWSへの接続では、GitHub Actionsから管理用AWSアカウントへOpenID Connect (OIDC)で接続し、そこから各アカウントのIAMロールを引き受けるという形にしました。OIDCを使うと簡単にGitHub ActionsでAWS管理の自動化ができるため、有り難い仕組みだなと思います。
まとめ
以上のようにして、Ansibleを利用して、オンプレミスにある仮想マシンのようにEC2インスタンスをまとめて操作することができるようになりました。
振り返ると、オンプレミスと比べたときの難しいところは、主に
- EC2インスタンスごとに必要な権限が異なること
- IPアドレスではインスタンスを見つけられないこと
- 通常のSSHでの接続ではなくSession Managerという独自形式での接続になること
に要約されます。これらの問題を、IAMロール引き受けとAnsibleのAWS関連モジュール(特にaws_ec2インベントリとaws_ssmプラグイン)を使うことにより解決できるという点が、本稿の伝えたかったことです。
本稿の情報が、多数のEC2インスタンスを抱える似たようなシステムの構築の際に役立てば嬉しいです。
ドワンゴでは、クラウド上に可用性・保守性・セキュリティに優れたシステムを構築・運用し、世界に誇る日本のコンテンツをたくさんの人々に届けにいく仲間を募集しています。ご興味がある方は、ぜひ採用情報ページをご覧ください。
また、本稿に関連する内容として、「実践Terraform:マルチAWSアカウント環境の構成管理とモジュール分割」の記事もぜひご覧ください。
参考文献
- 公式ドキュメント系(Ansible)
- 公式ドキュメント系(AWS)
- 公式ドキュメント系(GitHub)
- その他
-
AWSの「アカウント」は支払い管理やリソース隔離の単位となる最上位の管理境界のことを指す用語です。一人一人のユーザーに発行してログインに使う資格情報のことではありません(そちらはAWSでは「IAMユーザー」と呼びます)。「テナント」とか「契約単位」とか言った方がAWSを知らない人には通じやすそうに思います。Google Cloudの「プロジェクト」、Azureの「サブスクリプション」に概ね対応する単位です。 ↩︎
-
SSH以外にも、APIを叩くなどいろいろできます。 ↩︎
-
Ansibleというのはブランド名のようなもので、「Ansible」という名前がついたソフトウェアやサービスがたくさんあります。本記事で扱うのは Ansible Community です。 ↩︎
-
筆者は「ターゲットノード」という呼び名で覚えていたのですが、本記事を書くために調べたところ「マネージドノード」のほうが正式な名称のようでした。 ↩︎
-
厳密には、最初の2500文字だけはAPIで確認できます。 ↩︎
-
「クラウドはオンプレミスより劣化した」と言いたいわけではないです。先ほどの選択肢にあった「コントロールノード用のEC2インスタンスを用意して、そこから普通のSSHで接続する方法」を選ぶならば、つまりコントロールノード用EC2インスタンスを払い出して、マネージドノードのIPアドレスを固定して、コントロールノードとマネージドノードの間のTCP22番ポートの通信もセキュリティグループで許可するならば、Ansibleの伝統的な使い方もできます。あくまで、「クラウドらしい」あるいは「クラウドの利点を生かせる」構成を取るためには、少し発展的なAnsibleの使い方が必要になる、ということです。 ↩︎
-
amazon.aws.aws_ssm connection のドキュメントにはプレイブック側の
varsでansible_connection等の変数を設定する例が書かれていますが、これでは複数AWSアカウントに対応させるのが難しいです。ここで書いた例のように、インベントリのcomposeで指定するのがよいでしょう。 ↩︎ -
実際は
~/.aws/credentialsに認証情報が書かれている必要もあります。 ↩︎ -
なお、IAM Identity CenterのSSO機能でも似たことができるのですが、IAMユーザーを利用しなければならない場合やCI/CD関係を考慮して、IAMロールの引き受けを選びました。 ↩︎
-
実際はこのような仕組みはTerraformの実行用に既に整えていたため、それをAnsible用に横展開するだけでした。 ↩︎