AV1リアルタイムハードウェアエンコーダを開発しました
はじめに
AV1はAlliance for Open Media(AOM)が開発しているオープンかつロイヤリティフリーな動画圧縮コーデックです。 従来のコーデックよりも大幅に圧縮率が高く、同じデータ容量でも高画質な動画を表現できるため、4Kなどの大きなディスプレイの普及が進む現状において特に期待が寄せられています。 AOMには動画技術に関わる様々な企業が参加しており、注目の高さが伺えます。
そんなAV1ですが、エンコード処理時間に大きな課題を抱えています。 現在実装されているAV1ソフトウェアエンコーダを使用すると、ライブ配信が不可能なほど長い時間がかかるのです。 一般的に動画エンコードは時間がかかるものですが、その時間の大半は最適な設定を探索するために使われます。 AV1には高い圧縮率を実現するために非常に多くの機能が含まれており、その最適な設定の組み合わせを探索すると莫大な時間がかかってしまうというわけです。
公式のロードマップでは、PHASE 3にソフトウェア/ハードウェアのハイブリッドシステムの実装が挙げられています。
ソフトウェアだけでなくハードウェアも活用することで大幅な高速化が見込まれます。
ドワンゴの研究開発部ではAV1のハードウェアエンコーダを開発し、2019年3月時点で720p 30fpsのリアルタイム性能を達成しました。
システム構成
エンコード処理の流れと概要を以下に示します。
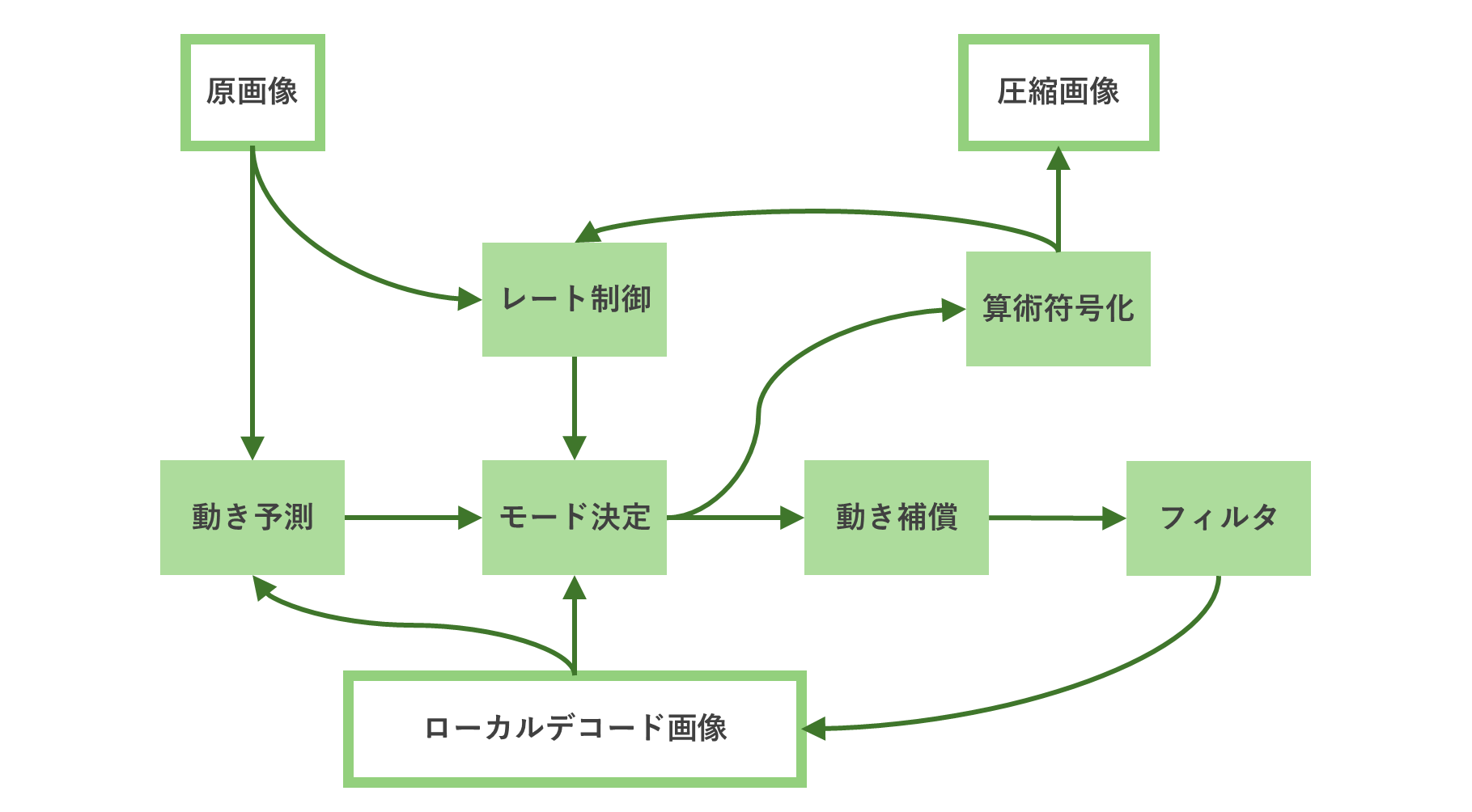
| 処理 | 概要 |
|---|---|
| 動き予測 | 動きベクトルを予測する |
| モード決定 | 画質劣化や発生符号量を見積もり、最適なモードを決定する |
| 動き補償 | 動きベクトルや様々な情報から予測画像を生成する |
| フィルタ | 予測画像をより元の画像に近づけるために補正する |
| 算術符号化 | エンコード画像を順に符号化する |
| レート制御 | 全体のビットレートを制御する |
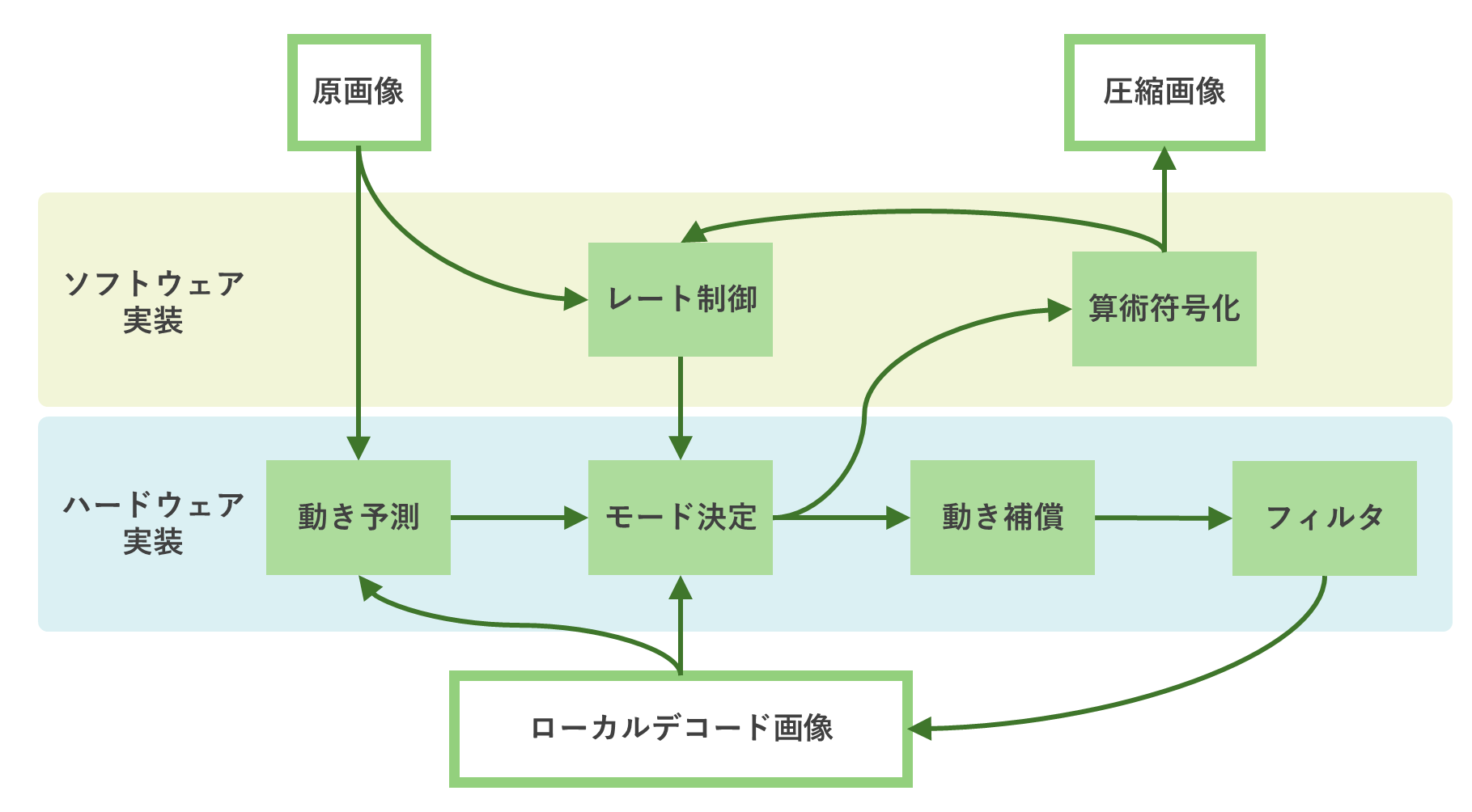
ハードウェア実装の利点の一つとして、並列処理が得意であることが挙げられます。
エンコード処理のうち、動き予測、モード決定、動き補償、フィルタについては並列化に向いている処理です。
特に動き予測、モード決定、動き補償は重い処理であるため、高速化することで全体の速度向上が期待できます。
算術符号化も重い処理ですが、これまでに符号化された情報を利用する必要があり並列化には向きません。
レート制御は細かな調整を行う可能性のある部分なので、ソフトウェア実装が向いていると思われます。
このような処理内容の特徴や想定デバイスの調査などを行い、最終的には以下のように、ハードウェアとソフトウェアを協調動作させる構成になりました。
ツール選定
AV1やH.264のようなコーデックの規格には、符号化効率を高めるための機能が多数定義されており、これらを符号化ツールと呼びます。
エンコード処理では、画質やデータ容量を加味して最適なツールの組み合わせと最適な設定を探し出します。
リアルタイム処理を目的としたエンコーダを開発する場合、規格上定義されたツールすべてをサポートして探索することは速度の面において現実的ではありません。
そのため、各エンコーダ独自の基準で符号化ツールのサブセットを作ることになります。
特にハードウェア実装の場合は回路規模を抑えるためにも機能を絞り込まなければいけません。
符号化ツールを削減することで計算量や回路面積を減らすことができますが、映像品質の低下をまねく恐れがあるため、注意深く削減する必要があります。
ツールの選定にあたっては、以下の点を考慮しました。
- 回路面積が大規模FPGA 1つに収まること
- 最大 FullHD(1920x1080) 30fps のリアルタイム処理が可能であること
- 実装時間が現実的であること
- 映像品質の低下ができるだけ少ないこと
AV1には多くの符号化ツールがありますが、今回の削減において検討した主な項目を以下に挙げます。
| ツール種別 | 概要 |
|---|---|
| 予測モード | イントラ/インター予測のモードの種類 |
| Superblockサイズ | 基本となるブロックのサイズ |
| Partitionタイプ | Superblock内をどのように分割するか |
| Blockサイズ | どこまで分割を進めるか |
| TXサイズ | 周波数変換を行うブロックの大きさ |
| TXタイプ | 周波数変換の基底関数の種類 |
| MV予測モード | インター予測における動きベクトルの予測方法 |
| 参照フレーム上限数 | インター予測で参照するフレームの参照可能上限数 |
選定作業にはAOMが公開しているソフトウェアエンコーダaomを使用し、改造によってツールを削減したときの映像品質を比較しました。
映像品質は一般的にビットレートと客観/主観画質のバランスで表されます。
客観画質とは計算によって数値化した画質のことで、代表的な手法としてはPSNRやSSIMがあります。
主観画質とは人の目で映像を評価した画質のことです。
今回は、客観画質としてPSNRを用いた指標(RD性能)を用い、映像品質を比較しました。
PSNRには"30dBを下回ると低品質である"といった基準はありますが、人の目で見たときの評価と必ずしも一致するわけではありません。
そこで、主観画質の評価も並行して実施し、多角的に映像品質低下を防止しました。
選定結果
まず、Superblockサイズを64X64と128X128とで比較しました。 その結果、テストケースのうち約75%でRD性能に変化がなかったため、全体の探索空間が小さくなる64x64を採用しました。 以降の実験では、Superblockサイズを64X64に固定した上で他の符号化ツールについて実験を行い、採用するツールを決定しました。
予測モードについては、画質がそれほど変化しないツールや実装上の問題があるツールを除外しました。 主なツールの選定理由は以下のとおりです。
- CfL: Chromaの予測にLumaの予測結果を利用するので、並列化が難しく回路規模が大きくなるため不採用
- IntraBC: インター予測相当の処理なのでインター予測器への機能追加で実現できるが、実装時間の都合で不採用
- Compound予測: 主観画質に大きな差はなく、ビットレートの増加も許容範囲であったため、AVERAGEのみに制限
- Motion Mode: Local WarpやOBMCは複雑な処理に対して得られるメリットが少ないと判断し、SIMPLEのみに制限
Partitionタイプは、イントラ予測では正方形分割のみ、インター予測では矩形分割も含める方が良いという結果になりました。 これはHEVCのPU分割と似たような選択であると言えます。
Blockサイズ/TXサイズは関連の強い項目なので、互いに考慮しながら選定しました。
イントラ予測では、TXサイズをBlockサイズよりも1段小さくすることでRD性能向上が見られたため、1段小さいTXサイズも探索対象としました。
インター予測ではその傾向があまり見られなかったので、TXサイズはBlockサイズと同じ大きさに固定しました。
TXサイズは小さく制限するほど画質が下がりますが、16X16サイズ以上のADSTには巨大な回路が必要になってしまいます。
回路面積削減のために、ADSTを採用したイントラ予測のTXサイズは8X8以下に制限しました。
TXタイプは当初、効率的な探索方法を模索していましたが、実装期間の都合により断念しました。 TXタイプを制限すると客観画質の差が生じますが、主観画質では許容可能な劣化だったので、イントラ予測では規格上のChroma処理を参考にしたテーブル引きを行い、インター予測ではDCTに固定としました。
MV予測モードは規格上で必須のモードが多く、想定よりもたくさんのモードを採用することになりました。
最終的に採用されたツールをイントラ予測/インター予測に分けてまとめると以下のようになります。
イントラ予測
| ツール種別 | AV1規格に存在するツール | 採用したツール |
|---|---|---|
| 予測モード | DC, SMOOTH, SMOOTH_V, SMOOTH_H, PAETH, Recursive(5モード), Directional(56方向), CfL, IntraBC, Palette | DC, SMOOTH, SMOOTH_V, SMOOTH_H, PAETH, Directional(56方向) |
| Partitionタイプ | NONE, SPLIT, HORZ, VERT, HORZ_A, HORZ_B, VERT_A, VERT_B, HORZ_4, VERT_4 | NONE, SPLIT |
| Blockサイズ | 4X4〜64X64 | 8X8〜16X16までの正方形 |
| TXサイズ | 4X4〜64X64 | 4X4〜8X8までの正方形 (Blockサイズと同じまたは1段小さいサイズ) |
| TXタイプ | DCT, ADST, IDTXの組み合わせ | DCT, ADSTの組み合わせ (テーブル引き) |
インター予測
| ツール種別 | AV1規格に存在するツール | 採用したツール |
|---|---|---|
| 予測モード | Single, Compound(AVERAGE, DISTANCE, DIFFWTD, WEDGE, INTERINTRA), MotionMode(SIMPLE, LocalWarp, OBMC), Skip, GlobalMotion, MotionField | Single, Compound(AVERAGE), MotionMode(SIMPLE), Skip |
| Partitionタイプ | NONE, SPLIT, HORZ, VERT, HORZ_A, HORZ_B, VERT_A, VERT_B, HORZ_4, VERT_4 | 変更なし |
| Blockサイズ | 4X4〜64X64 | 8X8〜32X32 |
| TXサイズ | 4X4〜64X64 | 8X8〜32X32 (Blockサイズと同じサイズ) |
| TXタイプ | DCT, ADST, FLIPADST, IDTXの組み合わせ | DCTのみ |
| MV予測モード | Single(NEAREST, NEAR x3, NEW x3), Compound(NEAREST_NEAREST, NEW_NEAREST, NEAREST_NEW, NEAR_NEAR x3, NEW_NEAR x3, NEAR_NEW x3, NEW_NEW x3) | Single(NEAREST, NEAR x3, NEW x3), Compound(NEAREST_NEAREST, NEAR_NEAR x3, NEW_NEW x3) |
| 参照フレーム上限数 | 7 | 2 または 3 |
※ “x3"の付いたMV予測モードには、それぞれの中にさらに3つのモードが存在する
結果
ここまで述べた構成やツール選定を踏まえ、FPGAアクセラレーションカードを想定して実装を行いました。
符号化ツールはかなり絞り込みましたが、それでも目標のリアルタイム性能や回路規模には届かない状態でした。
そこでハードウェア実装上の工夫として、大きなブロックの変換の効率化や、一部の予測モードを先に絞り込むなど、様々な試行錯誤を行いました。
その結果、720p 30fpsでのリアルタイムエンコードを達成することができました。
設計上の最大性能は1080p 30fpsリアルタイム処理であり、これはチューニング次第で達成できる見込みです。
他のエンコーダ、コーデックと画質を比較したグラフを以下に示します。
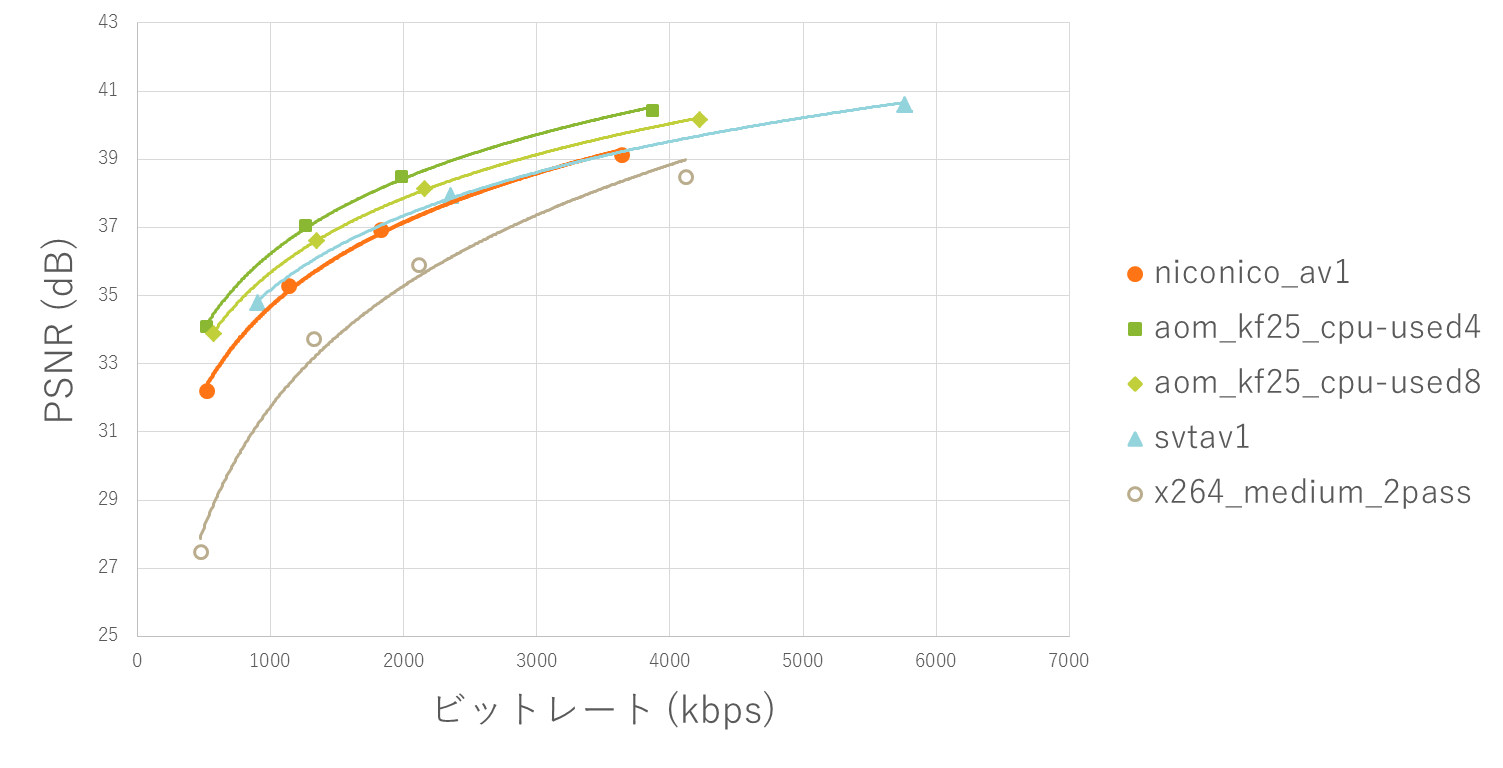
曲線が左上にあるほど画質がよいことを意味します。
“niconico_av1” が今回開発したエンコーダの結果です。
aomやSVT-AV1などのAV1ソフトウェアエンコーダと比較すると画質は落ちますが、大きく引き離されているわけではありません。
エンコード速度が数十〜数百倍になったことを考えると十分な結果です。
また、旧世代コーデックであるH.264のエンコード結果(x264)と比較するととても画質がよく、次世代コーデックとしての性能を発揮できたと言えるでしょう。
おわりに
AV1は非常に多くの機能を備えることで高圧縮率を実現していますが、そのすべてを使うことはエンコード速度など様々な面で現実的でありませんでした。 ツール選定のための実験では、全ての符号化ツールを有効にしたソフトウェアエンコーダを利用しましたが、小規模なエンコードでさえ長時間を要し、図らずもエンコード高速化の必要性を自ら実感することになりました。
しかし、機能を削ってもなお高い圧縮率を持つAV1には大きな魅力があります。 FPGAの世代が進むことで回路面積や動作速度の問題が緩和され、多くの機能を搭載した高速なエンコーダを実装できるかもしれません。 また、注目されているコーデックとして、高速なアルゴリズムや効率的な探索手法の研究が進んでいくことでしょう。 今後のAV1の発展に注目していきたいと思います。