Rust製の分散オブジェクトストレージをOSSとして公開しました
はじめに
ドワンゴではniconicoの配信系サービスのバックエンドで利用するために、Frugalosという名前の分散オブジェクトストレージを開発しているのですが、この度OSSとして公開することとなりましたので、この場を借りて軽く紹介させて貰います。
| https://github.com/frugalos |
FrugalosはRustで実装されており、現時点では以下のリポジトリが公開されています:
- raftlog_protobuf: raftlogへのProtocol Buffersサポートの追加
“Frugalos"って何?
“Frugal object storage"の略です。
“frugal"は日本語では「倹約な」や「節約する」といった意味となり、「読み書き性能を犠牲にせずに、膨大な数のBLOB(Binary Large OBject)を、容量効率良く保持する」ことを目指して開発されているオブジェクトストレージです。
提供されている機能はシンプルで、利用者は通常、以下の三つのHTTP APIを通してFrugalosを操作することになります:
# オブジェクトの新規保存・上書き
$ curl -X PUT -d {データ} http://localhost/v1/buckets/{バケツID}/objects/{オブジェクトID}
# オブジェクトの取得
$ curl -X GET http://localhost/v1/buckets/{バケツID}/objects/{オブジェクトID}
# オブジェクトの削除
$ curl -X DELETE http://localhost/v1/buckets/{バケツID}/objects/{オブジェクトID}※“バケツ"はオブジェクト群の管理単位で、事前に生成しておく必要があります
※その他の利用可能なAPIに関してはWikiを参照してください
どこで使われているの?
ニコニコ生放送の新配信システムで、タイムシフト番組の録画・配信用ストレージとして使用されており、今年の七月からユーザ向けの運用が始まっています。
参考(ニコニコインフォ): 【ユーザー生放送】タイムシフトが新配信システムに対応しました
現時点での規模感としては、1PiB超のデータを300個以上のHDDに分散して保持しており、ピーク時には1秒間で3GiB程度の読み書き要求を捌いています:
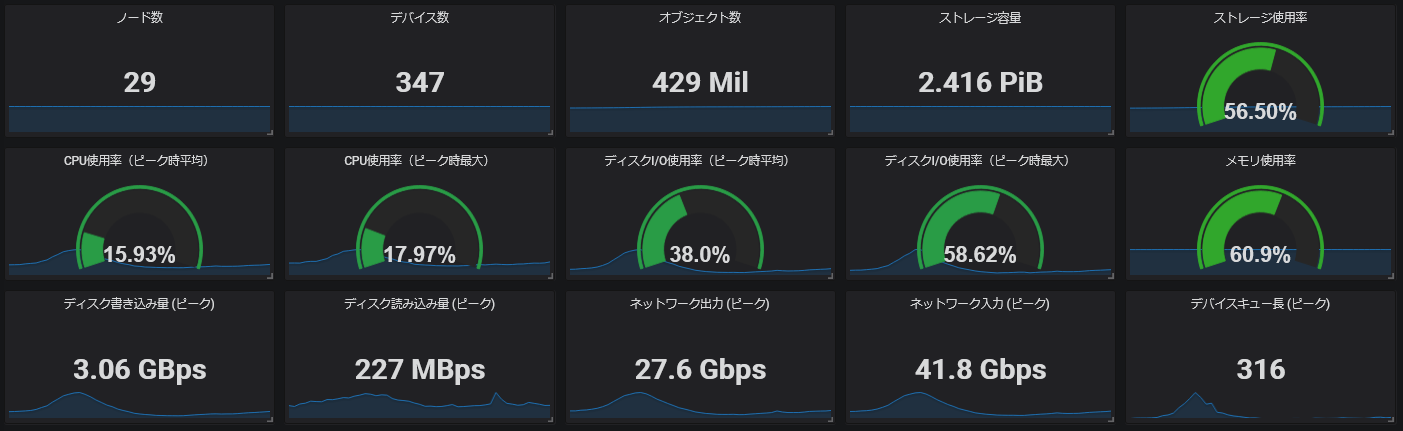
|
|---|
| ある日のGrafanaダッシュボード |
将来的には、投稿動画の保存・配信用途に使用する計画もあるのですが、そちらは現在は鋭意開発中となっています。
※ 現時点では、動画用途ではFrugalosとは別の、SSDベースの分散ストレージが使用されています
なぜ開発したのか
背景: 新配信システム移行に伴う要求ストレージサイズの増加
niconicoでは、日々たくさんの動画の投稿や生放送の配信が行われています。
もともと、それらを保存するために必要とされるストレージサイズは小さなものではなかったのですが、近年進めている新配信システム(そのバックエンド部分はDMCと呼称されることもあります)への移行に伴い、旧配信システムの頃に比べて、要求ストレージサイズが一桁以上大きなものとなった、という背景があります。
新配信システムで要求サイズが増大する要因としては、以下のようなものが挙げられます:
- 動画・生放送の高画質化:
- 新配信システムでは、動画・生放送の高画質化を進めています
- ユーザ生放送を例にすれば、旧配信システムでは配信ビットレート(上り)の最大値が480Kbpsだったのが、新配信システムでは6Mbpsとなっています
- つまり、新配信システムではユーザ生放送のタイムシフトを保存するために、旧配信システムに比べて10倍以上のストレージが必要となることになります(実際にはここまで単純な比較は行えないのですが、おおよその感触を掴む助けにはなるのではないかと思います)
- 映像・音声の複数品質への変換:
- 新配信システムでは、マルチデバイスや視聴者の多様なネットワーク環境に対応するために、同じソースを複数の品質に変換しています
- そのため、この変換数分だけ、追加のストレージが要求されることになりました
また、生放送のタイムシフトには(原則として)視聴期限が存在するため古いデータを削除することが可能なのですが、動画に関しては基本的に永遠に保持し続ける必要があるため、今後も要求ストレージサイズは増加の一途を辿ることが予想されます。
要求: HDDの使用とErasure Codingによる冗長化
この「ストレージサイズの大幅な増加」に対処するために、新配信システムの動画・生放送用ストレージに対しては、以下のような要求が(Frugalosの開発が決まる前から)挙がっていました:
- HDDを使いたい:
- 容量当たりのコストがSSDに比べて低いため
- 容量効率に優れたErasure Codingによる冗長化を行いたい:
- 一般的な、複製による冗長化では、容量的なオーバヘッドが無視できなかったため
- Erasure Codingの仕組みについての詳述は避けますが、機能的には「RAID6を一般化したもの」と考えて貰えれば、この記事を読む上では問題ありません
- RAID6とは異なり、データ分割の際のブロック数とパリティ数に任意の値が指定可能で、例えば「データブロック数は6で、パリティ数は3」といった設定にすれば、サイズ的なオーバヘッドを1.5倍に抑えたまま、3台までの故障に耐えられるようになります
- 分割後のブロックおよびパリティは、それぞれ別のサーバの別のHDDに保存されます
そのため、当初はErasure Codingに対応したOSSの分散ストレージの採用を検討していたのですが、 その性能検証を進めていくにつれて、次で取り上げる問題に直面することとなりました。
動画・生放送用ストレージのワークロードの特徴と難しさ
「ストレージサイズが巨大」ということに加えて、動画や生放送タイムシフトのワークロードには、以下のような特徴が存在します:
- アクセスパターンに局所性が期待できない:
- ニコニコ動画には大量の動画が存在しますが、一部の動画を除いて、大半のユーザは別々の動画を視聴しています
- ユーザ生放送のタイムシフトでも同様の傾向があり、番組数は多いですが、複数ユーザが同時に同じ番組を視聴していることは稀です
- そのため、一部の視聴が集中する動画・番組を除き、キャッシュヒット率はとても低いものとなります
- レイテンシが(視聴体験を損なわない程度には)安定して低い必要がある:
- 例えば、ストレージの読み込みレイテンシが大きいと、動画の視聴を開始したりシークする際に長時間待たされることになってしまいます
- また、視聴途中でデータの読み込みに時間が掛かってしまうと、映像や音声がそこで途切れてしまうかもしれません
- それを避けるために、ストレージの性能評価の際には「読み込み処理の99%は一秒以内に完了すること」といった制限を設けていました
- ストレージに対して読み書き両方の性能(スループット)が要求される:
- 動画と生放送タイムシフトの両方とも(例えば書き込みに特化したアーカイブストレージのようには)読み書きどちらかだけの性能に最適化することができない、といった難しさもあります
- 動画の場合:
- 新規投稿動画の保存用の書き込みが必要
- 動画視聴用の読み込みが必要(こちらの方が比重は高い)
- 生放送タイムシフトの場合:
- 生放送の録画用の書き込みが必要(こちらの方が比重は高い)
- タイムシフト視聴用の読み込みが必要
まとめると「読み書き両方のランダムなディスクアクセス」が発生し、「そこそこのレイテンシおよびスループット」が要求される、ということになりますが、これを達成するのはそう簡単ではないことがOSS製品の性能検証を進めるにつれて分かってきました。
ただでさえHDDはシーク速度が遅く、ランダムアクセスに弱いです。そこにErasure Codingによるデータ分割が加わると、ストレージ全体では分割数 + パリティ数倍のディスクアクセスが必要になってしまいます。
またErasure Codingでは、読み込み時に、分割されたデータブロック群を集めて元のデータを再構築する必要があります。その場合、対象データの読み込みレイテンシは「一番読み込みに時間が掛かったブロックのレイテンシ」に律速されることになります。つまり、ストレージ内の各ディスクのI/Oレイテンシのバラつきに対して、より敏感になってしまい、安定した低レイテンシを達成するのが難しくなります。
こういった要因が重なり、残念ながら、検証を進めていた既存の分散ストレージでは要求性能を満たすことができませんでした。
HDDの限界性能の検証とFrugalosの開発開始
「既存ストレージをniconicoのワークロードに当てはめて使用する」というアプローチが行き詰ってしまったので、次は方向性を変えて「HDDを最大限に活用できたとしたら、期待する性能が達成可能なのか」を検証することになりました(もしこれが無理なら、そもそもの選択が間違っていたことになります)。
この時に作成したプロトタイプは、現在Frugalosのローカルストレージとして使用されているCannyLSの前身となるのですが、以下のような特徴を備えていました:
- PUT/GET/DELETE操作を備えたローカルオブジェクトストレージ
- 各操作で必要なディスクアクセス(シーク)回数に厳密な上限がある:
- PUTなら二回、GET/DELETEなら一回
- レイテンシおよびスループット低下を防ぐために、インデックスやメタデータは全てメモリ上に保持
- ダイレクトI/Oを使用して、OSのキャッシュ層(ページキャッシュ)はバイパス:
- ページキャッシュが存在すると、不確実性が増え、レイテンシのバラつきが大きくなってしまう可能性があるため
- また、基本的にランダムアクセスを想定しているため、キャッシュの意義は薄い
- オブジェクトサイズとしては、数百KiB~数MiBを想定:
- あまり巨大なオブジェクトが扱われると、それに対するディスクI/Oが他の操作を長時間ブロックし、レイテンシのブレが大きくなってしまうため
- 逆にあまり小さ過ぎると、ディスクのシークコストが相対的に高くなり、今度はスループットが低下してしまいます
- メモリのGCの影響を回避するために、プログラミング言語にはGCの無いRustを選択
つまり、HDDを高速化するために何か特別な機構を追加した、というよりは、ランダムアクセスは必ず発生するものと諦めた上で無駄を極限まで削ぎ落とした形になります。
当時の検証結果ではないのですが、参考のために、CannyLSのベンチマーク結果の一部を載せておきます。
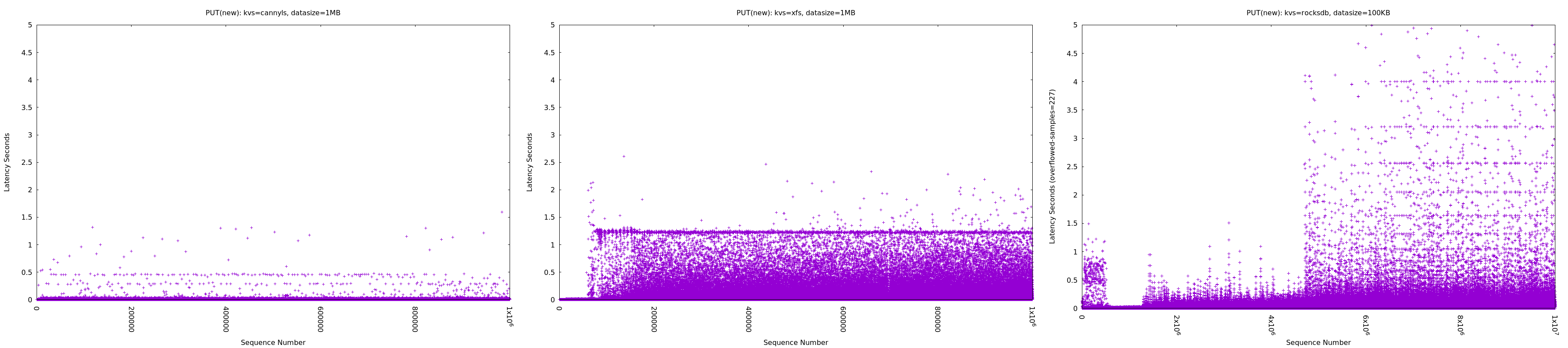
|
|---|
| https://github.com/frugalos/cannyls/wiki/Benchmark より一部結果を抜粋 |
このベンチマークではHDDに対して「サイズが1MiBのオブジェクト(CannyLS用語では“lump”)を、合計1TiB分だけPUT(保存)する」といった処理を実行しています(X軸は何番目のPUTかを、Y軸は各PUTに要した時間を、示しています)。
左の図はCannyLS、中央は「一オブジェクトを一ファイル」としたファイルシステム(XFS)、右の図はRocksDBという組み込みKVS、をストレージとして使用した結果になります。右二つに関しては、HDD用に特別な最適化が行われている訳ではないためあくまでも参考結果に過ぎませんが、それでもCannyLSの場合には(ある程度)一貫して安定した低レイテンシが維持されていることが見て取れるのではないかと思います。
この単体HDDでの検証結果を、niconicoが要求するワークロードに照らし合わせてみたところ、どうやらHDDの性能を最大限活用できれば、要求性能も満たせそうだということが分かりました。
※ なおここで触れたもの以外にも、ローカルストレージ部分には様々な工夫が施されている(e.g., ディスクI/Oの使用効率を高めるためのデッドラインベースのI/Oスケジューリング)ため、興味のある人はCannyLSのWikiを参照して貰えればと思います
これで原理上は、HDDでも大丈夫そうだということが判明したため、次はこのプロトタイプにErasure Codingを用いた分散・冗長化層を追加し、分散オブジェクトストレージとして最低限の機能を備えた状態にしました。さらに、それをバックエンドとして利用した簡易的な動画の配信サーバを実装し、実際の投稿・視聴パターンを模したベンチマークを実施してみましたが、ここでも期待通りの性能が出ていることが確認できました。
この段階で性能面での懸念点は解消でき、一通りの見通しが立ったため、分散オブジェクトストレージの開発が正式に始まり、今に至ります。
配信バックエンド全体の中での立ち位置
Frugalosの立ち位置を明確にするために、タイムシフトの録画および視聴時のストリームの流れを示した図を掲載しておきます:
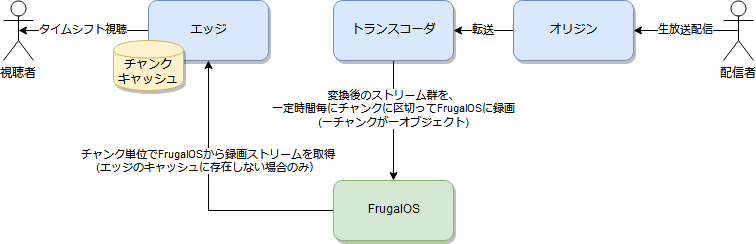
|
|---|
| タイムシフト録画・視聴時のストリームの流れ |
実はFrugalosは「ストレージミドルウェアのためのミドルウェア」といったような立ち位置で使用されることを想定しています。
Frugalosは性能(HDDの活用効率)や可用性、スケーラビリティには優れていますが、提供している機能は最低限で制限も少なくないため、動画ファイルやタイムシフトストリームをそのまま格納する用途には向いていません。
例えば、制限の一つとして「巨大なオブジェクト(e.g., 数百MiB)は保存できない」といったものが挙げられます。公式生放送の場合には、長いものでは24時間を超える番組があり、そのストリームサイズは数十GiB単位となるのですが、当然このストリーム全体をそのまま一つのオブジェクトとして、Frugalosに保存することはできません。
そのため(それだけが理由ではないですが)上の図でも、生放送ストリームは、トランスコーダノード上でチャンクという小さなオブジェクトに分割された上で、Frugalosに保存されるようになっています。
同様に、視聴時にそのチャンク群から実際のタイムシフトストリームを復元することもエッジノードの責務となっています。 また公式生放送番組では、同じタイムシフト番組に対して視聴が集中することが良くあるのですが、そういったアクセス集中に対応するためのキャッシュの仕組みも、Frugalosではなくエッジノードが備える形となっています。
つまり、一般に「分散ストレージ」という言葉で想起されるような機能は、Frugalos単体では提供されておらず、 その前段にある別の層と組み合わせて初めて、実際に有益な、ストレージとしての機能が利用可能になります。
新配信システムのバックエンドにおける、このFrugalosの前段に位置する層に関して、今回は詳しく触れることはありませんが、 機会があればまたどこかで詳しく紹介させて貰うかもしれません。
技術的な特徴
興味のある方がいるかもしれないので、Frugalosの技術的特徴を簡単に列挙しておきます:
- ほぼ完全にRust製:
- Erasure Codingによる冗長化:
- 残念ながら現状はCライブラリのラッパーを使っており、ここだけがRustではない
- Raftを最大限に活用:
- HDD特化のローカルストレージ:
- 上で触れた通り「安定した低レイテンシ」をHDD上で達成するために、いろいろと頑張っている
- 詳細はCannyLSのWikiを参照
- メトリクスや分散トレース:
- メトリクス収集はPrometheusで、分散トレースはJaegerで実現
- ただし分散トレースの方は、まだ対応が部分的なので、これから拡充予定
なお、Frugalosのアーキテクチャや実装の詳細に関してGitHubのWikiに記載していく予定ですので、今後はそちらを参照して貰えればと思います(今はほとんど空ですが…)。
苦労話
せっかくの機会なので、開発・運用で苦労した点をいくつか紹介させて貰います。
※ 蛇足的な内容なので、各トピックに興味がない人は、読み飛ばしを推奨します
Rustでの非同期サーバ実装手法が確立されていなかった
そもそも開発当初はfuturesすら登場していなかったので、ネイティブスレッドやeventual、rotor等を使って、Rustでの非同期I/Oの実装方法を模索していました。
その後、futuresがリリースされた以降は、コードをfuturesを使用するように書き換えていった訳ですが、その当時はまだtokioも十分に使える状態ではなく、似たような機能を提供するfibersを自分達で実装していたりしました。
futuresの使用が確定した後も、それを効率的に利用するためのイディオムが固まるまでには長い時間を要し、非同期I/Oが絡む部分のコードは何度も全面的に書き直すことになりました。
今では、知見もだいぶ溜まり、futures関連部分のコードが(対応する同期版の実装に比べて)かなり冗長になることを除けば、概ね満足のいく設計・実装が出来るようになりましたが、ここに至るまでにはだいぶ回り道をしてしまいました。
そのため、Rustで非同期処理を記述しやすくするためのasync/await構文が導入される予定の2018エディションは、とても楽しみにしています! (おそらく、2018エディションリリース後のどこかで、また大幅なコードの書き直しが発生するとは思いますが…)
稼働中の分散システムのデバッグが困難
niconicoの新配信システムでは、Erlangが主要な開発言語として使われているのですが、Erlangの場合は本番運用中に何か問題が発生した際に、稼働中のErlangVMにアタッチして、各種情報を収集したり、トレースを取ったり、あるいはVM上で直接任意の関数を実行したり、といったことが簡単に行えます。
それに慣れてしまっていたということもあり、Rustで実装された稼働中のサーバのデバッグを行うのが、当初はだいぶ困難でした。 当然、Rustでは「一度起動したサーバにアタッチする」といったことは(少なくとも気軽には)行えないですし、ログは出力していましたが、今回の規模の分散システムでは、ログだけで、問題ないしその兆候を特定するのは、かなり骨の折れる作業でした。そもそも必要なログが出力されておらず、プログラムの修正・再デプロイ・問題再現待機、を繰り返したことも何度もあります。
これを改善するために、Frugalosの開発中盤では、ひたすらPrometheusメトリクスを仕込む作業を行っていた時期がありました。 現在では、ローカルストレージや内部RPC部分も含めて、合計で71種類のメトリクスが収集されていますが、これによりクラスタ全体の状況把握や異常検知がかなり行いやすくなりました。
またJaegerによる分散トレースも部分的に導入されており、これによっていくつかレイテンシ上のボトルネックが解消できました(以下の図はHLS視聴時のトレースの例)。
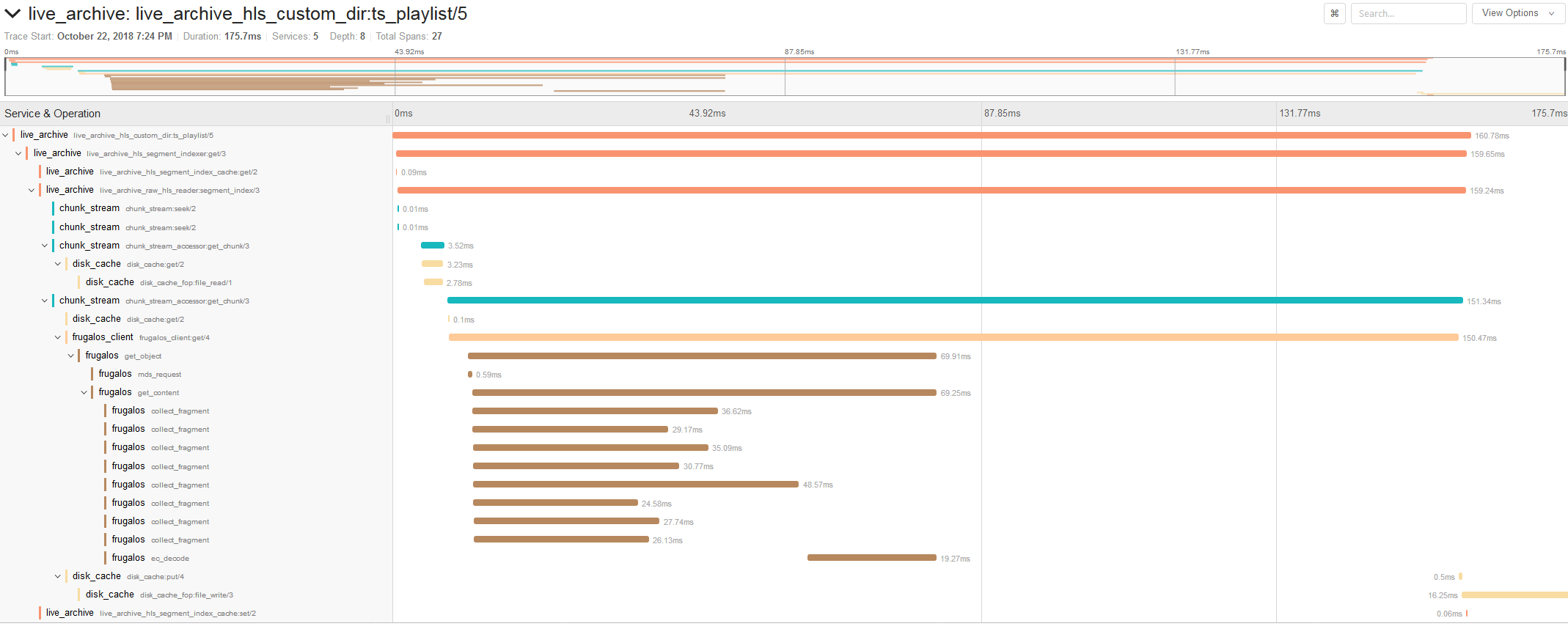
|
|---|
| JaegerによるHLS視聴リクエスト処理のトレース例 |
それ以外に、デバッグ用のAPIも機会を見つけて実装してはいるのですが、これはまだ十分な数が揃っているとは言い難い状況です。
jemallocのメモリ使い過ぎ問題
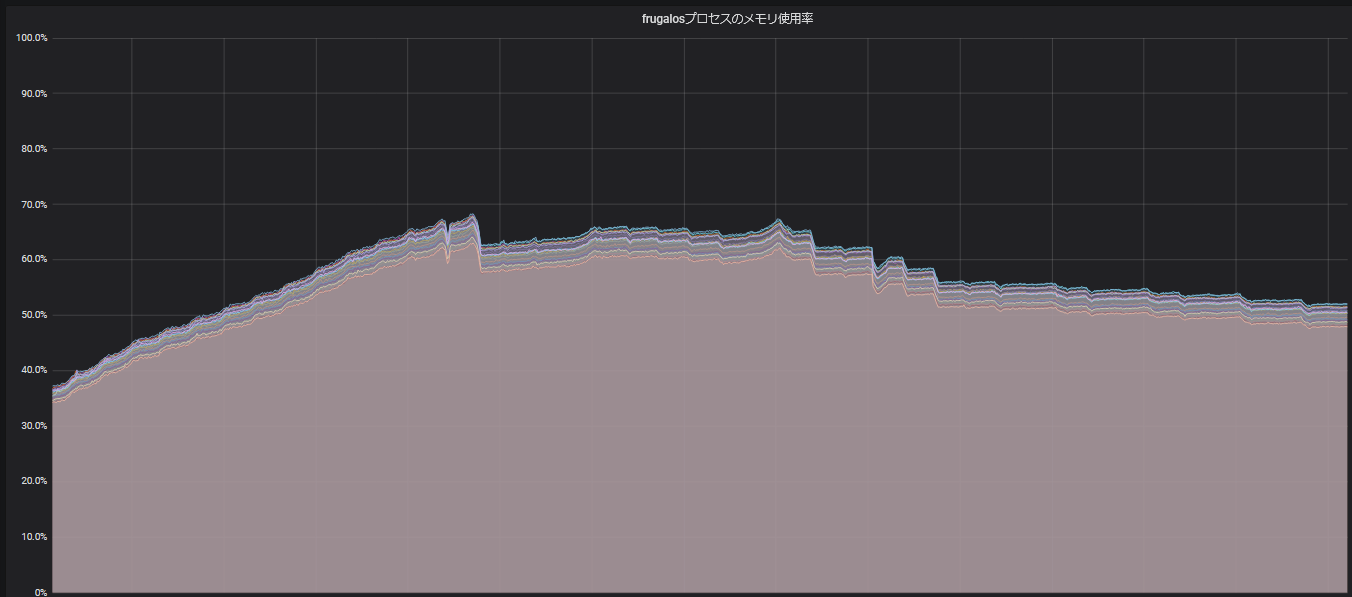
Rustではjemallocというメモリアロケータがデフォルトで使用されているのですが、これが原因でFrugalosのメモリ使用量が実際よりも大幅に多く見えてしまう、という問題に遭遇したことがありました。
以下の図は、Frugalosの起動後から一カ月半が経過するまでの期間を切り取って、そのメモリ使用量を示したものになりますが、 frugalosプロセスのメモリ使用量が山のような形状を取って推移していることが分かります(この期間中、オブジェクトの保存数自体には大きな変動がありませんでした):
|
|---|
| frugalosプロセスのメモリ使用量の推移 |
このピーク時のメモリ使用量は、どう考えても予測量よりも多いものであり、ピークを過ぎて下降し始めるまでは、メモリリークでも発生しているのではないかと肝を冷やしたものです。
結局現時点でも詳細な理由は判明していないのですが、jemalloc-ctlを使ってjemallocの統計情報をダンプしてしたところ、必要量よりも多めにメモリを(アロケータ用に)確保していそうだということが判明したため、jemallocのチューニングガイドを参考に、メモリ使用量を抑えるようなオプションを環境変数で指定するようにしたところ、上の図のような山を描くことはなくなりました。
C言語のライブラリ部分でセグメンテーションフォールトが発生
Erasure Coding部分に関してはC言語で実装されたライブラリを採用している、という話は上でも書きましたが、このライブラリ部分でセグメンテーションフォールトが発生したためにプログラムがクラッシュしてしまう問題に、何度か遭遇しました。
一番困ったのは、特定のパラメータでErasure Codingのエンコーダを生成した場合に、初期化や通常のエンコード・デコードは成功するけれど、欠損したデータの復元を行おうとした場合にだけ、セグメンテーションフォールトが発生する、といった問題でした。
結局、これ自体はRustコードでのバリデーションを強化することで対処を行ったのですが、長期間稼働するサーバでの予期せぬ実行時エラーの怖さを再認識しました。
serdeが非同期シリアライズに非対応
Rustにはserdeという便利なシリアライゼーションライブラリが存在するため、当初はFrugalosの内部通信用に、serdeとHTTPを組み合わせたRPCを使用していました。
ただserdeは、非同期的なシリアライズ・デシリアライズに対応しておらず、これがサイズの大きいメッセージ(e.g., オブジェクトデータ、Raftのスナップショット、要素数が多いRaftのログエントリ配列)を送受信する機会が多いFrugalosでは問題となることが、次第に分かってきました。 こういったメッセージをserdeを使って同期的にシリアライズ・デシリアライズしてしまうと、その間、該当非同期タスクを実行しているスケジューラスレッドの実行がブロックしてしまうことになりますが、それが累積してシステム全体の大幅な遅延に繋がってしまうことがあったのです。このブロック問題を解消するだけであれば、serde部分だけを別のスレッドプール上で実行すれば回避可能ではあるのですが、serdeが非同期処理に対応していないために、非同期I/Oと組み合わせるためには、シリアライズ・デシリアライズのための一時バッファが必要となり、余計なアロケーションとメモリコピーが一回増えてしまう、という別の問題もありました。
このような問題に対処するために、内部RPC部分は最終的には非同期処理に対応した独自のもので置き換えることになりました (ただし、将来的にはgRPCの採用も検討したいと考えています)。
分散システムあるある
ある程度の規模の分散システムを運用した経験がある方であれば分かるのではないかと思いますが、 そういったシステムを長期間運用しているとマシンやディスクの故障は日常的に発生します。
実はFrugalosのユーザリリースの前には、録画だけを行う試験運用期間が半年以上あったのですが、 その間に故障周りの問題には一通り遭遇したのではないかと思います。
当然、事前に故障を想定した設計はしていたのですが、想定外の状況であったり、あるいは単に実装漏れによって、 クラスタ全体の停止やスローダウンに繋がるような状況に陥ったことも何度かあります。
以下はその一例を挙げておきます:
- マシン停止の検知漏れ:
- マシンの停止やプロセスダウン自体は適切に処理されるようになっていたのですが、その検知方法に漏れがあり、該当マシン(上のプロセス)に対する内部RPCのメッセージ群が「送信待機」の状態で溜まってしまい、タイムアウトが頻発する、といった問題がありました
- HDDの読み書き速度が極端に遅くなる:
- これは設計段階から想定してはいたのですが、ローカル環境での再現が難しかったこともあり、実際の運用中にHDDの速度低下が発生した際には、それに影響されて(予想外に)遅くなってしまう箇所がいくつかあることが判明しました
- なお、この問題に対処するためにmizumochiというツールを開発し、ローカルでも手軽にディスクの速度低下を模倣可能なようにしました
- メモリがスワップアウトしたマシンに引き摺られて、他のマシンのメモリ使用量も増加:
- 故障等により、一定期間切り離されていたマシン(上のfrugalosプロセス)を再起動すると、Raftによる同期処理が実行されます
- 上でも少し触れましたが、Frugalosではストレージクラスタ内の多数のRaftクラスタが存在しているため、この同期処理も複数Raftクラスタによって並行的に行われることになるのですが、その際の並行度が高すぎて(ネットワーク速度に対してCPU処理が追い着かずに)該当マシンのメモリが不足しスワップアウトが発生することがありました
- 再起動マシンにだけ問題が閉じているのであればまだ良いのですが、そのスワップアウトが発生したマシンに対する別のマシンからの内部RPCも詰まってしまい、送信側キューにメッセージが溜まり続け、そちらのメモリも徐々に逼迫していく、という連鎖的な問題に繋がってしまいました(結局この時は、同期中の再起動プロセスを強制終了することで対処しました)
幸い、ユーザリリース後は安定して動作してくれていますが「適切な耐障害性を備えていること」の網羅的な検証手段の確立は、 まだ重要な課題として残っています。
おわりに
Frugalosはコードを公開して、今後はOSSとして開発していくこととなりましたが、 まだまだ足りていないものは無数にあるので、これから徐々に整備していけたらと考えています。
例えば簡単に思いつくだけでも、以下のような試したいことが残っています:
- 消費メモリサイズを節約するために簡潔データ構造の導入
- ローカルストレージのアロケータの改善やデフラグ機能の実装
- Erasure Coding部分をRust実装に置き換える
- 内部通信のgRPC化
- カオスエンジニアリングの拡充
- POSIX準拠のファイルシステムインタフェースの実装
- 他にもS3やストリーミング配信に特化したインタフェースもあると便利
もしこの辺りの技術分野や、Frugalosのようなプロダクトを生み出せる環境で働くことに興味がある方がいましたら、是非採用ページからの応募をご検討頂ければと思います。 もちろん、OSSとして公開されたリポジトリへのコントリビュートも歓迎です!