モニタリング #
言わずもがな、サーバーを持ちサービスを運用する上でモニタリングは必須です。 収集したログや Metrics は不正アクセスや障害の検知、アラートの発報などサービスの運営をする上で必ず必要な情報です。
利用しているモニタリングツール #
今回利用しているモニタリングツールは以下の 2 つがあります。
| Explorer | DashBoard | |
|---|---|---|
| 1 | Prometheus | Grafana |
| 2 | DataDog Agent | DataDog |
2 つ存在する理由は、費用的な面とツールの精度を確認するための理由があります。
- DataDog は本番環境で使う。一部の開発環境でも検証可能な状態で利用する。
- 上記の DataDog を使わない環境では Prometheus と Grafana で代用する
- 2つのツールでモニタリングの精度を比較する(本来は最低でも 3 つあったほうが良い)
どちらも同じ Metrics を収集できるため単体での Observability の差に大きく違いはありません。 ただ DataLakeとしてDataDogがすでに基盤として存在しているためメインは DataDog に各種情報が集約されています。
BFF サーバーの何を観測するか #
BFF サーバーにおいて観測する主要なものは以下の表にまとめました。 どれも時系列データとして記録されるため時間変化が分かる状態になっています
BFF サーバーとして主に観測しているのは次のようなメトリクスになります。
※ 略語
- rps = Request Per Seconds (1秒間あたりのリクエスト数)
| メトリクス | 目的 |
|---|---|
| CPU 使用量の最大値、平均値、合計値 | 想定値との比較 |
| Memory 使用量の最大値、平均値、合計値 | メモリリークの観測、想定値との比較 |
| HTTP Status Codeの数 | 200, 300, 400, 500 系の観測 |
| リクエスト総数に対するStatus Code 500 の数 | エラー率の観測 |
| マイクロサービス間のResponse Time(HTTP, GRPC) | ボトルネックの観測 |
| マイクロサービス間のrps | 実効rpsが想定内か観測する |
| Node ごとの replicas | スケールアウトやデプロイの変化を観測する |
BFF以外はアクセスログを出力するfluent-bitや、RateLimitを実施しているマイクロサービスも監視する対象となります。
DataDogの例 #
具体的な例を紹介します。 DataDog のKubernetes タグ抽出では粒度の低いタグとして、 Kubernetes のRecommend Labelsが利用できます。
| DataDog のタグ | Kubernetes の Pod Label |
|---|---|
kube_app_name | app.kubernetes.io/name |
kube_app_instance | app.kubernetes.io/instance |
kube_app_version | app.kubernetes.io/version |
kube_app_component | app.kubernetes.io/component |
kube_app_part_of | app.kubernetes.io/part-of |
kube_app_managed_by | app.kubernetes.io/managed-by |
TypeScriptでKubernetesのmanifestを記述するで紹介したように、これらのラベルを機械的に付与していくとDataDog上での分解能が飛躍的に向上します。
最も利用頻度の高いタグはkube_app_nameとkube_app_versionで、これらの2つは非常に重要な役割を担います。
例えば、新しいPodをデプロイした際に、kube_app_versionをフィルタリングのクエリとして利用することで、
どの時刻で新旧のバージョンが入れ替わったのかが可視化されます。
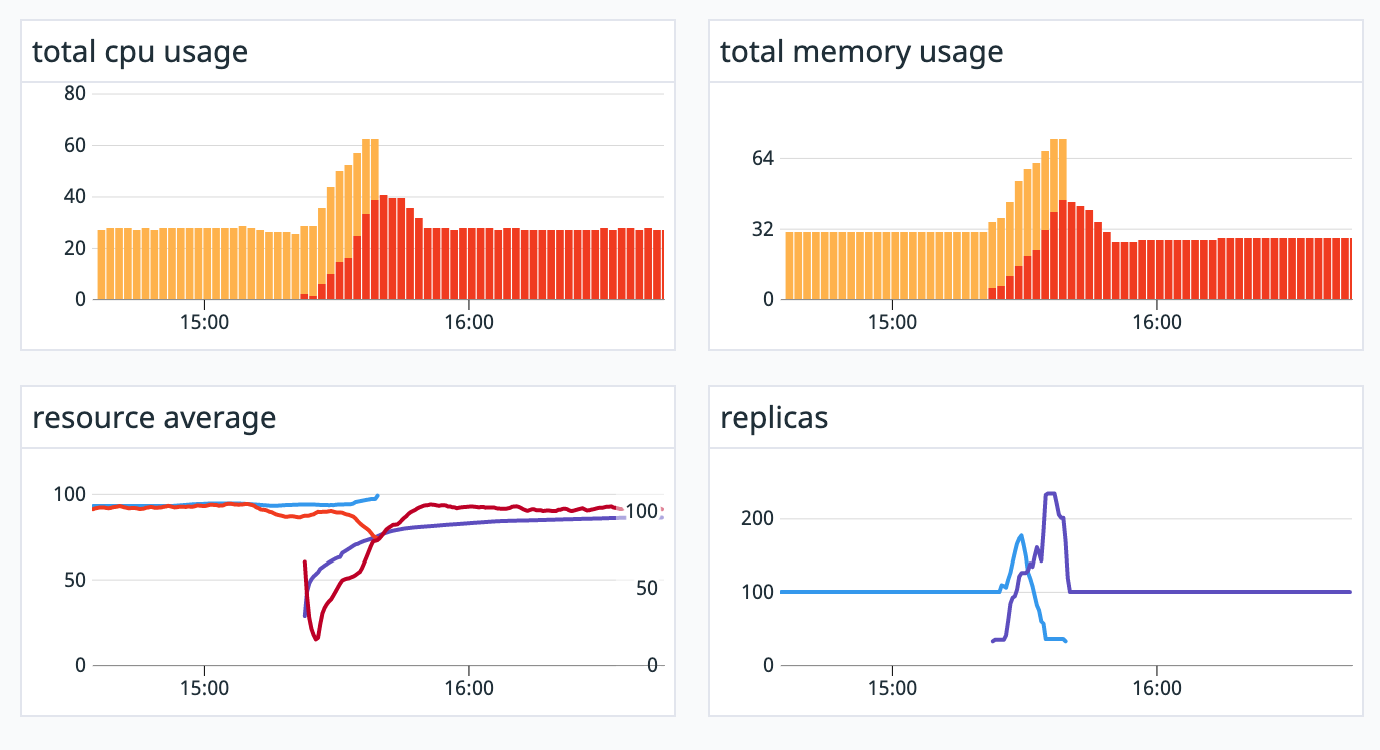
DashBoardでは他の指標と見比べる事が可能ですので、例えば新しいバージョンにバグが有り、マイクロサービス間の通信のエラー率が高まった場合の観測が可能です。
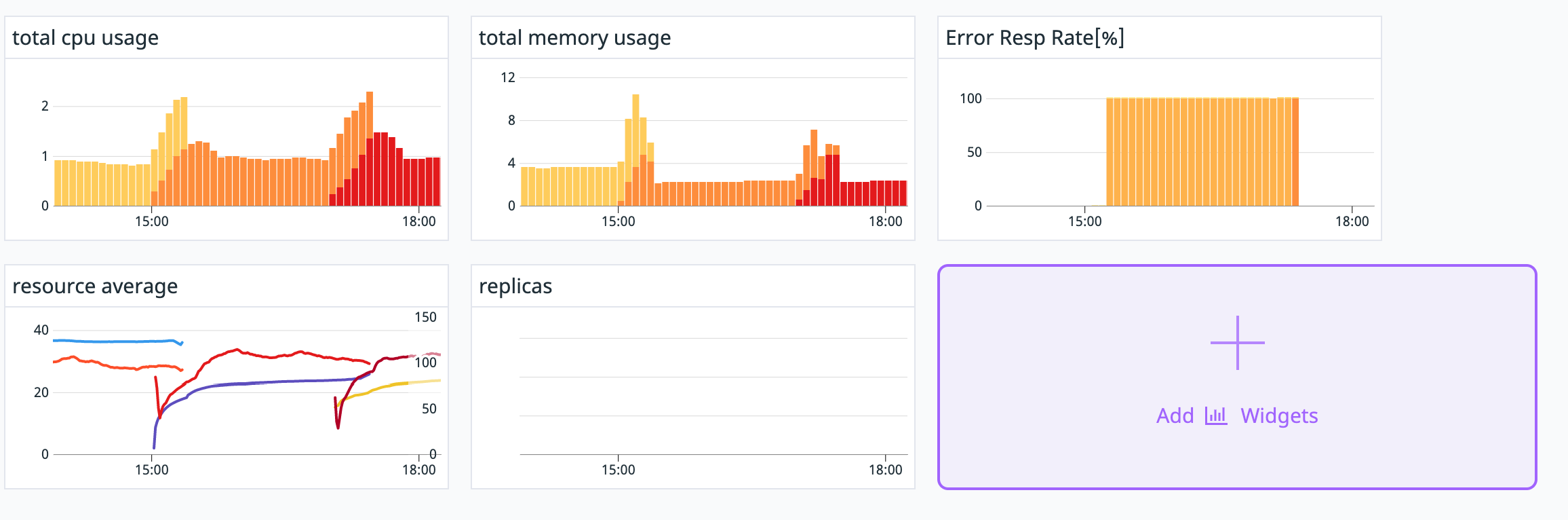
上記のクエリは次のようになっています。
Template Parameter
$kube_app_name$kube_namespace
# Total CPU Usage
autosmooth(sum:kubernetes.cpu.usage.total{$kube_app_name,$kube_namespace} by {kube_app_version})
# Total
autosmooth(sum:kubernetes.memory.usage{$kube_app_name,$kube_namespace} by {kube_app_version})
# Error Resp Rate[%]
a / b * 100
## a
sum:istio.mesh.request.count.total{response_code:5*,$kube_app_name,$kube_namespace} by {response_code,destination_service,request_protocol,kube_app_version}.as_count()
## b
sum:istio.mesh.request.count.total{$kube_app_name,$kube_namespace} by {destination_service,request_protocol}.as_count()
より高度な演算が可能なため、Error Resp Rate[%]のように複数のMetricsを組み合わせることが可能です。
モニタリングの次にやること #
更新のたびにDashboardを見に行き、バグがないか確認するはいわゆる「トイル」な仕事になります。 Argo RolloutsではProgressive Deliveryを支援するためのAnalysis機能があり、 PrometheusやDataDogなどの集計データをもとにデプロイを続行するかどうか自動的に判断する事が可能です。
これを導入するためにはまずは信頼できる指標の作成が必要で、 BFFサーバーは何を指標とするかはこれから吟味が必要です。